Amazon EC2 で Diagnostic Interrupts (診断割り込み) がサポートされました。Diagnostic Interrupts というと馴染みがないと思いますが、実際は Non Maskable Interrupt (NMI) が送信されます。本稿でも以下、NMI と呼ぶことにします。
NMI とは
割り込み(Interrupt)は ある特定の条件が発生した時に、現在実行中の処理を一旦中断して、事前に指定した別の処理(割り込みルーチン)を実行する仕組みです。
割込みは大きくハードウェア割り込みとソフトウェア割り込みに分けられます。
ハードウェア割り込みはすごく単純に言うと物理的に CPU に割り込み用のボタンが付いていて、それを押すと対応した処理が実行される仕組みです。
一方のソフトウェア割り込みは割込み発生命令によって擬似的に割り込みを発生させる仕組みです。
また処理の内容によっては、割込みして欲しくない場合や一時的に無視したい場合に割り込みを禁止できるようになっています。割り込みを隠すので、割り込みをマスクするといいます。
しかしそれでもなお強制的に何らかの処理を実行させたい場合に備えてマスクできない割り込みが用意されています。マスクできないので、"Non Maskable" と呼ばれています。
今回導入された、Diagnostic Interrupts (診断割り込み) はこの NMI を仮想マシン上に発生させるものです。
Diagnostic Interrupts (診断割り込み)/NMI を使用するユースケース
このような割り込みを強制的に発生させたい場合とはどのような場合でしょうか?通常の処理中であれば割り込みの制御はオペレーティングシステム(OS)に任せておいて問題ないはずです。とすると通常でない何らかの事象が発生した場合に利用することが想定されます。
例えば無限ループで暴走していて全く操作を受け付けない状態や、デッドロックなどで処理が全く進まなくなってしまった場合、想定外の高負荷状態で操作を全く受け付けないなどが考えられます。
その場合でもリセットやインスタンスのストップ・スタートなどで回復することは可能ですが、できることならば何らかの診断メッセージを表示させて根本原因を究明し対策を実施できる方が好ましいでしょう。
ログからある程度わかると言う場合もあるかと思いますが、異常な処理状態ではログも正確に出力されるとは限りません。
そこで Diagnostic Interrupts (診断割り込み)/NMI により強制的に処理を中断させ、特定の診断ルーチンを実行することが考えられます。ノート PC やデスクトップ PC ではあまり見かけないかもしれませんが、信頼性が求められるサーバ PC では NMI ボタンが用意されていることが多いです。
Dell PowerEdge R330 オーナーズマニュアル より

Diagnostic Interrupts (診断割り込み)/NMI と kdump
Linux OS ではこのような診断機構として、kdump が利用される場合があります。kdump は kernel パニックが発生した場合に、メモリの内容を一旦ハードディスクなどの永続媒体に一旦保存し後から解析できるようにする仕組みです。このようにメモリの内容を出力しデータをクラッシュダンプと呼びます。
原因不明の再起動が発生する場合や、突然サーバが停止、ハングアップする場合などクラッシュダンプを調べることで原因を特定できる場合があります。
また高負荷時の負荷状態を確認するためにクラッシュダンプを調べることで負荷の状態がわかる場合があります。
kernel バグの調査でも役立つ場合があります。
Diagnostic Interrupts (診断割り込み)/NMI による kdump 実行の設定
それでは実際に kdump を設定してクラッシュダンプを採取してみたいと思います。今回 OS としては Amazon Linux 2 を利用します。なお設定方法に関しては、EC2のマニュアルに記載がありますので、合わせてご確認ください。
Amazon Elastic Compute Cloud User Guide for Linux Instances Sending a Diagnostic Interrupt (Advanced Users Only)
前提条件
まず前提条件を確認します。以下ディストリビューションとして、"Amazon Linux 2" を利用します。
kdump を利用する前提として、NITRO 世代のインスタンスを利用する必要があります。これは、NITRO 世代以前はハイパーバイザとして XEN を利用していましたが、XEN では仮想 NMI によるクラッシュダンプ採取に対応していないためです。NITRO 世代ではハイパーバイザが KVM に変更されたため、仮想 NMI によるクラッシュダンプの採取が可能になっています。
NITRO ベースのインスタンスタイプは以下のマニュアルに記載があります。
Amazon Elastic Compute Cloud User Guide for Linux Instances Nitro-based Instances
以下のインスタンスタイプが NITRO 対応であると載があります。
- A1, C5, C5d, C5n, I3en, M5, M5a, M5ad, M5d, p3dn.24xlarge, R5, R5a, R5ad, R5d, T3, T3a, and z1d
- Bare metal: c5.metal, c5n.metal, i3.metal, i3en.metal, m5.metal, m5d.metal, r5.metal, r5d.metal, u-6tb1.metal, u-9tb1.metal, u-12tb1.metal, and z1d.metal
ARM ベースの A1 インスタンスタイプは、kdump に対応していないので注意してくださあい。
kvm で動作しているかどうかは例えば以下のコマンドラインで確認できます。
$ lscpu | grep Hyper Hypervisor vendor: KVM
もしくは
$ systemd-detect-virt kvm
また比較的最近の AMI を利用する必要があります。以前はそもそも仮想 NMI がサポートされていなかったので、Amazon Linux / Amazon Linux 2 ではカーネルのコンパイルオプションで kdump が有効になっていませんでした。いつから有効になっているのか正確に把握できていませんが、直近のバージョンであれば問題ないと思います。また OS のアップデートを行わずに古いまま利用しているとセキュリティ上あるいはコンプライアンス上問題になるケースがあると思いますので可能な限りアップデートをお勧めします。
利用中の kernel で kdump が有効になっているかどうかは、kernel と同時にインストールされる /boot/config-x.y.z-a.b.amzn2.x86_64 (x,y,z,a,b はバージョンを表す数字) ファイルで確認することができます。例えば以下のコマンドラインで確認します。
$ grep CRASH_DUMP /boot/config-$(uname -r) CONFIG_CRASH_DUMP=y
kdump 用の kernel 専用にメモリ領域を確保する必要があるので搭載されているメモリが 1 GB 以上ある必要があります。もし、メモリ領域を確保した結果、アプリケーションで使用するメモリが不足するような場合は、別途インスタンスサイズもしくはインスタンスタイプの変更を検討する必要があります。
搭載されているメモリ量は例えば以下のコマンドラインで確認します。
$ grep MemTotal /proc/meminfo MemTotal: 7865400 kB
なお確認したメモリの量は後で設定時に必要となるので、控えておいて下さい。
kexec ツールの導入と設定
kdump はクラッシュダンプ採取用のカーネルへの切り替えに kexec という機構を利用します。本来は実行中に新しいカーネルを読み込むための機構ですが、kdump の切り替え用にも利用されています。 ツールの導入自体はパッケージで簡単に行えます。
$ sudo yum install kexec-tools -y
kernel 起動時コマンドラインオプションの追加
クラッシュダンプ kernel 用の専用メモリ領域を指定します。起動時コマンドラインオプションに "crashkernel=<メモリ量>" オプションを追加します。必要なメモリ量は搭載しているデバイス数や CPU 数などによって代わってきます。
必要なメモリ量の目安は、例えばredhat 社のサイトが参考になるでしょう。
「カーネルの管理、監視、および更新」/ 6. kdump のインストールと設定/6.5. サポートしている KDUMP の設定とダンプ出力先/6.5.1. kdump メモリー要件
上記より一部を抜粋します。
| 使用可能なメモリ | 最小予約メモリ |
|---|---|
| 1GB から 64GB | 160 MB のメモリ |
| 64GB から 1TB | 256 MB のメモリ |
| 1TB 以上 | 512 MB のメモリ |
メモリのオフセットを指定することもできます。"crashkernel=160M@16M" などのように指定できますが、通常は自動設定で問題ないと思います。
設定は /etc/default/grub ファイルの GRUB_CMDLINE_LINUX_DEFAULT で始まる行に記載します。vim などお好きなエディタを利用してください。
変更前
GRUB_CMDLINE_LINUX_DEFAULT="console=tty0 console=ttyS0,115200n8 net.ifnames=0 biosdevname=0 nvme_core.io_timeout=4294967295 rd.emergency=poweroff rd.shell=0" GRUB_TIMEOUT=0 GRUB_DISABLE_RECOVERY="true"
変更後
GRUB_CMDLINE_LINUX_DEFAULT="crashkernel=160M console=tty0 console=ttyS0,115200n8 net.ifnames=0 biosdevname=0 nvme_core.io_timeout=4294967295 rd.emergency=poweroff rd.shell=0" GRUB_TIMEOUT=0 GRUB_DISABLE_RECOVERY="true"
GRUB2 に以下のコマンドラインで設定を反映させます。
$ sudo grub2-mkconfig -o /boot/grub2/grub.cfg
ここまで設定したら一旦再起動しましょう
$ sudo shutdown -r now
クラッシュダンプ出力用 EBS ボリュームの作成とアタッチ
出力されるクラッシュダンプのファイルはメモリと同等かそれ以上のサイズが出力されるため、メモリの使用状況によりますが、非常に大きなファイルが出力される場合があります。そのためファイルシステムを圧迫したり、出力する領域が不足して全てのデータを書き出せない場合も想定されます。
そのため専用の出力領域を確保した方が一般的には良いでしょう。
なお、出力されるクラッシュダンプのファイルサイズは最大搭載メモリ量と追加ヘッダ部分が出力されるので、メモリの使用状況やダンプ出力フィルタの指定、圧縮の有無などによりますが、搭載メモリよりも大きくなる場合があります。そのため私は個人的には少し余裕を持って搭載メモリのざっくり倍程度の領域を確保しています。
ダンプ出力の EBS ボリュームを例えば以下の様な手順で確保します。
#1. インスタンス ID の確認
$ echo $(curl -s http://169.254.169.254/latest/meta-data/instance-id )
i-05f53abe650333443
#2. リージョンと AZ の確認
$ echo $(curl -s http://169.254.169.254/latest/meta-data/placement/availability-zone )
us-west-2b
#3. EBS ボリュームの確保
$ aws ec2 create-volume --region us-west-2 --availability-zone us-west-2b --size 16
{
"AvailabilityZone": "us-west-2b",
"Tags": [],
"Encrypted": false,
"VolumeType": "gp2",
"VolumeId": "vol-04b91d2b13301a724",
"State": "creating",
"Iops": 100,
"SnapshotId": "",
"CreateTime": "2019-09-06T07:47:37.000Z",
"Size": 16
}
#4. EBS ボリュームの状態確認
# "State:" が "available" になっていることを確認する。
$ aws ec2 describe-volumes --region us-west-2 --volume-ids vol-04b91d2b13301a724
{
"Volumes": [
{
"AvailabilityZone": "us-west-2b",
"Attachments": [],
"Encrypted": false,
"VolumeType": "gp2",
"VolumeId": "vol-04b91d2b13301a724",
"State": "available",
"Iops": 100,
"SnapshotId": "",
"CreateTime": "2019-09-06T07:47:37.496Z",
"Size": 16
}
]
}
#5. インスタンスのデバイス名の確認
# jq コマンドがインストールされていない場合は、
# "sudo yum install -y jq" コマンドでインストールすること
$ aws ec2 describe-instances --region us-west-2 --instance-ids i-05f53abe650333443 | jq '.Reservations[].Instances[].BlockDeviceMappings[]'
{
"DeviceName": "/dev/xvda",
"Ebs": {
"Status": "attached",
"DeleteOnTermination": true,
"VolumeId": "vol-0af9ffecc8ef2d2c0",
"AttachTime": "2019-09-02T06:12:33.000Z"
}
}
#6. インスタンスへのボリュームのアタッチ
# インスタンスで利用できるデバイス名は /dev/sd[f-p]*
# もしくは /dev/xvd[f-p]* が推奨されている。
# /dev/sd[b-e] はインスタンスストアボリュームで使用することが推奨
# https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/device_naming.html
$ aws ec2 attach-volume --region us-west-2 --instance-id i-05f53abe650333443 --volume-id vol-04b91d2b13301a724 --device /dev/xvdf
{
"AttachTime": "2019-09-24T06:03:22.799Z",
"InstanceId": "i-05f53abe650333443",
"VolumeId": "vol-04b91d2b13301a724",
"State": "attaching",
"Device": "/dev/xvdf"
}
#7. インスタンスにアタッチ出来たことを確認
$ aws ec2 describe-instances --region us-west-2 --instance-ids i-05f53abe650333443 | jq '.Reservations[].Instances[].BlockDeviceMappings[]'
{
"DeviceName": "/dev/xvda",
"Ebs": {
"Status": "attached",
"DeleteOnTermination": true,
"VolumeId": "vol-0af9ffecc8ef2d2c0",
"AttachTime": "2019-09-02T06:12:33.000Z"
}
}
{
"DeviceName": "/dev/xvdf",
"Ebs": {
"Status": "attached",
"DeleteOnTermination": false,
"VolumeId": "vol-04b91d2b13301a724",
"AttachTime": "2019-09-24T06:03:22.000Z"
}
}
パーティションの作成とフォーマット
以下通常の Linux でのパーティションの作成とフォーマットです。特に理由がなければファイルシステムとして ext4 を指定します。
#1 デバイス名の確認
$ ls -l /dev/xvdf
lrwxrwxrwx 1 root root 7 Sep 24 06:03 /dev/xvdf -> nvme1n1
#2 念の為デスクが空であることを確認する
# 作成したばかりなので、ファイルシステムが表示されない。
$ sudo file -s /dev/nvme1n1
/dev/nvme1n1: data
#3 GPTラベルの作成
$ sudo parted /dev/nvme1n1 mklabel gpt
Information: You may need to update /etc/fstab.
#4 パーティションの作成
$ sudo parted /dev/nvme1n1 mkpart primary 0% 100%
Information: You may need to update /etc/fstab.
#5 確認
# 上記コマンドラインで実行した場合、パーティションの前後に 1MB 程度の使用されない領域ができる。
# 通常そのままで問題ないと思われるが、気になる場合は
# パーティション作成時に "-a none" オプションを使用すると回避できる
$ sudo parted /dev/nvme1n1 print free
Model: NVMe Device (nvme)
Disk /dev/nvme1n1: 17.2GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
17.4kB 1049kB 1031kB Free Space
1 1049kB 17.2GB 17.2GB primary
17.2GB 17.2GB 1032kB Free Space
#6 フォーマット
# フォーマット以前にプレウォーミングしても良いがここでは省略する。
# フォーマットは色々対応しているが、ここではブートディスクに合わせて xfs とした
$ sudo mkfs -t xfs /dev/nvme1n1p1
meta-data=/dev/nvme1n1p1 isize=512 agcount=4, agsize=1048448 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=0
data = bsize=4096 blocks=4193792, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
/etc/fstab への登録
/etc/fstab に記載するにあたって、blkid コマンドで対象ファイルシステムの UUID を確認します。Linux では再起動時にデバイス名と実際の対応するデバイスが入れ替わることがあるため、ファイルシステムに固有のIDである、UUIDを使用します。
$ sudo blkid -p -s UUID /dev/nvme1n1p1 /dev/nvme1n1p1: UUID="fe8b48c9-d4f1-4303-b35e-24978f199ada"
/etc/fstab に以下の1行を追記します。UUID は先ほど確認した値で置き換えてください。
UUID=fe8b48c9-d4f1-4303-b35e-24978f199ada /var/crash xfs defaults,noatime 1 1
記載内容に誤りがないか mount -a コマンドなどで正常にマウントできることを確認してください。
/etc/kdump.conf の設定
kdump の設定ファイルである、/etc/kdump.conf を編集します。 最低限以下の3行を記載します。"#" (シャープ) 記号はコメントアウトです。 詳細は man 5 kdump.conf を参照してください。
# 出力先のファイルシステムとファイルシステムの UUID # UUID は /etc/fstab に記載したものと同じ xfs UUID=fe8b48c9-d4f1-4303-b35e-24978f199ada # 出力先のパス # 出力先ファイルシステムのルートから記載する。 # 今回は専用のファイルシステムを用意しているので "/" path / # クラッシュダンプファイルを生成するコマンドラインの指定 # 通常は、makedumpfile コマンドを使用する。 # makedumpfile の詳細は man 8 makedumpfile を参照 core_collector makedumpfile -c -d 0 # ここで使用しているオプション # -c zlib で圧縮 # -d ダンプ出力時に省略するメモリ領域。0 で省略しない
そのほかにユーザとして興味深いオプションとして、ダンプ出力後にリブートするか、停止するかを指定することができます。特に指定しない場合はリブートします。以下のように指定した場合は再起動せず停止します。インスタンス課金を避けるために halt ではなく poweroff を指定しています。
default poweroff
/etc/sysctl.conf の設定
NMI によるパニックを有効にするために、sysctl の設定を行います。以前は /etc/sysctl.conf に直接記載する形式が主流でしたが、現在は /etc/sysctl.d/ 配下に設定ごとに固有のファイルを作成して記載する形式になっています。
ここでは "99-kernel_panic.conf" というファイル名で以下の内容を記載しました。記載にあたってはスーパーユーザ(root)権限が必要となることに注意してください。
kernel.unknown_nmi_panic=1
ただ折角 kdump を利用できるように設定したので他の不具合でもダンプ出力するように設定した方が良いでしょう。現在のカーネルで利用できるダンプ関係の設定は以下のものがあります。
以下に kernel 添付文書の sysctl/kernel.txt から引用します。
- kernel.hardlockup_panic
- ハードロックアップを検出した場合にパニックするかどうか
0 - ハードロックアップ時にパニックしない(デフォルト)
1 - ハードロックアップ時にパニックする - kernel.hung_task_panic
- ハングタスクを検出した際にパニックするかどうか
0 - 処理を継続する(デフォルト)
1 - 直ちにパニックする - kernel.panic
- パニック時に再起動するまでの秒数
- kernel.panic_on_io_nmi
- IO エラーによる NMI を CPU が受信した時にカーネルの振る舞いをコントロールする。
0 - 処理を継続するように試みる(デフォルト)
1 - 直ちにパニックする。IO エラーが NMI をトリガーしたということは、IO データ破壊を引き起こす深刻なシステム状態であることを示しているので、処理を継続するよりもパニックする方が良い選択かもしれない。いくつかのサーバはダンプボタンが押された場合にこの種類のNMIを発行するのでこのオプションをクラッシュダンプを採取するのに利用できる。 - kernel.panic_on_oops
- oops(kernel のエラー) もしくは BUG() 関数が実行された場合にカーネルの振る舞いを制御する
0 - 処理の継続を試みる(デフォルト)
1 - 直ちにパニックする。kernel.panicパラメータがゼロ以外ならばマシンは再起動する - kernel.panic_on_rcu_stall
- 1 に設定するとRCU (kernel で利用されている排他制御機構の一種) がストール(停止) しているのを検出した時に panic() 関数を呼び出す。 RCUストールの根本原因を確定するのに役立つ
0 - RCU ストールが発生しても panic()を呼ばない(デフォルト)
1 - RCU ストールメッセージを出力して panic() を呼ぶ - kernel.panic_on_stackoverflow
- ユーザスタックを除く、kernel、IRQ、例外スタックのオーバーフローを検出した時のカーネルの挙動を制御する。
0 - 処理の継続を試みる(デフォルト)
1 - 直ちにパニックする - kernel.panic_on_unrecovered_nmi
- デフォルトの Linux でメモリもしくは未知の NMI を検出した際の動作は処理の継続である。科学計算のような多くの環境では、訂正不能なECCやパリティエラーが広がるよりも、筐体が取り出されエラーが適切に処理されることが好まれる。
一部のシステムではパワーマネジメントのような奇妙で根拠のない理由で NMI を生成するのでデフォルトではオフになっている。この sysctl は既存のパニックコントロールと同じように機能する。 - kernel.panic_on_warn
- 1 にセットすると WARN() 関数内で panic()関数を呼び出す。WARN() の箇所で kdump を試みたい時に kernel の再構築を省くのに役立つ。
0 - WARN() だけ実行する(デフォルト) 1 - WARN() の場所を出力した後で panic() を呼び出す。 - kernel.softlockup_panic
- ソフトロックアップを検出した場合にパニックするかどうか
0 - ソフトロックアップ時にパニックしない(デフォルト)
1 - ソフトロックアップ時にパニックする
上記のうちサイトのレギュレーションにもよりますが、"kernel.panic_on_oops" ぐらいは有効にしておいたほうがいいでしょう。
ここまで設定したら、再度設定を反映させるために再起動します。
AWS CLIの最新化
2019年10月3日現在 Amazon Linux 2 でパッケージとして配布されている、AWS CLI のバージョンはaws-cli/1.16.102,botocore/1.12.92 となっています。しかし send-diagnostic-interrupt サブコマンドは aws-cli/1.16.218,botocore/1.12.208 以降から利用可能になっています。そこで本稿作成時点では pip 等を利用して AWS CLI の最新版をインストールする必要があります。
今回は後で簡単にアンインストールできるように、virtualenv コマンドを利用してインストールしたいと思います。他の python プログラムと競合しないとか特に追加インストールにこだわりがないような場合は "pip install awscli" として直接インストールしても良いでしょう。
#1 必要なパッケージのインストール $ sudo yum install -y python2-pip python-virtualenv #2 仮想環境の作成 $ virtualenv awscli New python executable in /home/ec2-user/awscli/bin/python Installing setuptools, pip, wheel...done. #3 仮想環境配下に移動 $ cd awscli #4 仮想環境の有効化 $ source bin/activate #5 awscli のインストール $ pip install awscli (長いので省略)
これで send-diagnostic-interrupt サブコマンドが実行できるようになります。
send-diagnostic-interrupt の実行
ここまでくると実際にクラッシュダンプを採取できるようになっていると思います。 実際に NMI を送信して採取してみましょう。
以下のコマンドラインを実行します。インスタンス id 等は各自の環境に合わせて読み替えてください。
$ aws ec2 send-diagnostic-interrupt --region us-west-2 --instance-id i-05f53abe650333443
もし該当インスタンスに ssh 接続している場合は再起動するので接続が切断されます。 /etc/kdump.conf で default 行を指定していない場合は、自動的に再起動するのでしばらく待ってから再接続しましょう。
$ aws ec2 get-console-output --instance-id i-05f53abe650333443 --region us-west-2 | jq -r .Output
kdump が正常に実行された場合は以下のようなログ出力が見受けられると思います。
........
Starting Kdump Vmcore Save Service...
kdump: dump target is /dev/nvme1n1p1
kdump: saving to /kdumproot/var/crash///127.0.0.1-2019-10-03-07:47:45/
kdump: saving vmcore-dmesg.txt
kdump: saving vmcore-dmesg.txt complete
kdump: saving vmcore
Copying da[2019-10-03T07:47:55.314625]ta : [ 9.3 %] /Copying data [2019-10-03T07:48:07.314659] : [ 21.7 %] /Copying data [2019-10-03T07:48:19.314715] : [ 34.1 %] /Copying data [2019-10-03T07:48:31.314760] : [ 46.4 %] /Copying data : [ [2019-10-03T07:48:43.314894]58.8 %] /Copying data : [ 71.2 %] / [2019-10-03T07:48:55.31494Copying data : [ 83.6 %] / eta[2019-10-03T07:Copyi[2019-10-03T07:49:20.314941]ng data : [ 92.5 %] |Copying data [2019-10-03T07:49:32.314960] : [ 98.0 %] |Copying data : [100.0 %] | eta: 0s
The dumpfile is saved to /kdumproot/var/crash///127.0.0.1-2019-10-03-07:47:45/vmcore-incomplete.
makedumpfile Completed.
kdump: saving vmcore complete
........
出力されたクラッシュダンプの確認
出力されたダンプファイルは、/var/crash 配下に、"127.0.0.1-日付-時刻"の形式でディレクトリが作成され、その中に vmcore という名前のファイルに格納されます。
$ ls /var/crash 127.0.0.1-2019-10-03-07:47:45 $ ls /var/crash/127.0.0.1-2019-10-03-07\:47\:45/ vmcore vmcore-dmesg.txt
vmcore ファイル調査するためには、crash コマンドと kernel のシンボル情報などを格納した、debuginfo パッケージが必要になります。それぞれ以下のコマンドラインで導入します。 なお、このようなデバッグツールの導入は各サイトのセキュリティレギュレーションで制限されている場合があるので注意が必要です。
$ sudo yum install -y crash $ sudo debuginfo-install -y kernel
展開された kernel のシンボル情報は以下のファイルに格納されています。バージョン部分はご利用中の環境に合わせて適宜読み替えてください。
/usr/lib/debug/lib/modules/4.14.146-119.123.amzn2.x86_64/vmlinux
debuginfo パッケージのバージョンと、解析対象の vmcore の生成元になった kernel のバージョンが完全に一致している必要があるので注意してください。現在実行中のバージョンは "uname -r" コマンドで確認できます。
vmcore の内容は例えば以下のコマンドラインで確認できます。
$ sudo crash /usr/lib/debug/lib/modules/4.14.146-119.123.amzn2.x86_64/ vmlinux /var/crash/127.0.0.1-2019-10-03-07\:47\:45/vmcore
実行すると以下のような出力があり、crash 用のプロンプト "crash>" が表示されて解析用のコマンドを入力できるようになります。
crash 7.2.6-1.amzn2.0.1
Copyright (C) 2002-2019 Red Hat, Inc.
Copyright (C) 2004, 2005, 2006, 2010 IBM Corporation
Copyright (C) 1999-2006 Hewlett-Packard Co
Copyright (C) 2005, 2006, 2011, 2012 Fujitsu Limited
Copyright (C) 2006, 2007 VA Linux Systems Japan K.K.
Copyright (C) 2005, 2011 NEC Corporation
Copyright (C) 1999, 2002, 2007 Silicon Graphics, Inc.
Copyright (C) 1999, 2000, 2001, 2002 Mission Critical Linux, Inc.
This program is free software, covered by the GNU General Public License,
and you are welcome to change it and/or distribute copies of it under
certain conditions. Enter "help copying" to see the conditions.
This program has absolutely no warranty. Enter "help warranty" for details.
GNU gdb (GDB) 7.6
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-unknown-linux-gnu"...
KERNEL: /usr/lib/debug/lib/modules/4.14.146-119.123.amzn2.x86_64/vmlinux
DUMPFILE: /var/crash/127.0.0.1-2019-10-03-07:47:45/vmcore
CPUS: 2
DATE: Thu Oct 3 07:47:41 2019
UPTIME: 00:05:30
LOAD AVERAGE: 0.16, 0.13, 0.08
TASKS: 115
NODENAME: ip-10-0-0-14.us-west-2.compute.internal
RELEASE: 4.14.146-119.123.amzn2.x86_64
VERSION: #1 SMP Mon Sep 23 16:58:43 UTC 2019
MACHINE: x86_64 (2500 Mhz)
MEMORY: 7.7 GB
PANIC: "Kernel panic - not syncing: NMI: Not continuing"
PID: 0
COMMAND: "swapper/0"
TASK: ffffffff82013480 (1 of 2) [THREAD_INFO: ffffffff82013480]
CPU: 0
STATE: TASK_RUNNING (PANIC)
crash>
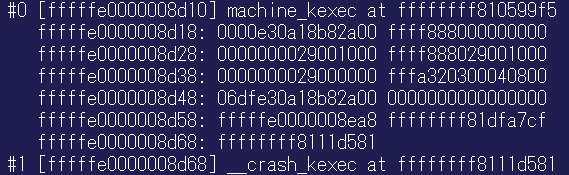
試しに bt (バックトレース) コマンドを実行すると、swapper を実行していた cpu 0 が NMI を受信して、kexec を実行していることが確認できます。
crash> bt
PID: 0 TASK: ffffffff82013480 CPU: 0 COMMAND: "swapper/0"
#0 [fffffe0000008d10] machine_kexec at ffffffff810599f5
#1 [fffffe0000008d68] __crash_kexec at ffffffff8111d581
#2 [fffffe0000008e28] panic at ffffffff81088df2
#3 [fffffe0000008eb0] nmi_panic at ffffffff810889d5
#4 [fffffe0000008eb8] unknown_nmi_error at ffffffff8102eaff
#5 [fffffe0000008ed0] do_nmi at ffffffff8102ed9b
#6 [fffffe0000008ef0] end_repeat_nmi at ffffffff81801937
[exception RIP: native_safe_halt+14]
RIP: ffffffff81617a5e RSP: ffffffff82003eb0 RFLAGS: 00000246
RAX: ffffffff81617720 RBX: ffffffff821ddea0 RCX: 0000000000000000
RDX: 0000000000000000 RSI: 0000000000000000 RDI: 0000000000000000
RBP: 0000000000000000 R8: ffff88822d01cf00 R9: 0000000000000000
R10: 0000000000000000 R11: 0000012f49e147fb R12: 0000000000000000
R13: ffff88822d355e80 R14: 0000000000000000 R15: 0000000000000000
ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018
--- <NMI exception stack> ---
#7 [ffffffff82003eb0] native_safe_halt at ffffffff81617a5e
#8 [ffffffff82003eb0] default_idle at ffffffff8161773a
#9 [ffffffff82003ed0] do_idle at ffffffff810cdec4
#10 [ffffffff82003ef0] cpu_startup_entry at ffffffff810ce0cf
#11 [ffffffff82003f10] start_kernel at ffffffff82490fe2
#12 [ffffffff82003f50] secondary_startup_64 at ffffffff810000d5
終了するには quit コマンドを入力します。
なお、vmcore ファイルはなるべく早く退避して、/var/crash 配下のファイルを削除してください。次に何らかの panic が発生した場合に容量不足避けるためです。
最後に
これで Diagnostic Interrupts の動作確認が一通りできたと思います。普段あまり利用することはないかもしれませんが、万が一の備えとして覚えておいてもいいかも知れません。









