Glueジョブで日付形式の文字列をApplyMapping変換で認識させようとしたらうまく行かなかったので、代わりにSQL Queryを使用して認識させてみました。
やりたいこと
- 入力データのCSVをGlueジョブで変換し、Glueテーブルに出力する。
- Glueテーブルは適切なデータ型にする。
2022/01/01という日付形式をtimestamp型として変換する。
入力データ
今回、Glueで処理する入力となるCSVデータはこのデータとします。
日付の区切りがハイフンではなくスラッシュになっています。
|
1 2 3 4 5 |
id,name,updatedat 1,"すごい たろう","2020/01/15 03:44:40" 2,"ものすごい じろう","2022/10/12 05:12:59" 3,"とんでもない さぶろう","2022/03/15 12:34:56" 5,"はんぱない ごろう","2021/10/29 23:55:10" |
出力テーブル
こんな感じのGlueテーブルに出すことを目標とします。
- データストア:S3バケット
- カラム一覧:
id(int)name(string)updatedat(timestamp)
- パーティション:なし
- 保存形式:parquet (データそのものがデータ型を持っていれば何でもOK)
テスト環境の作成・実行
環境を用意する必要がありますので、下記の手順で環境を作って試してみます。
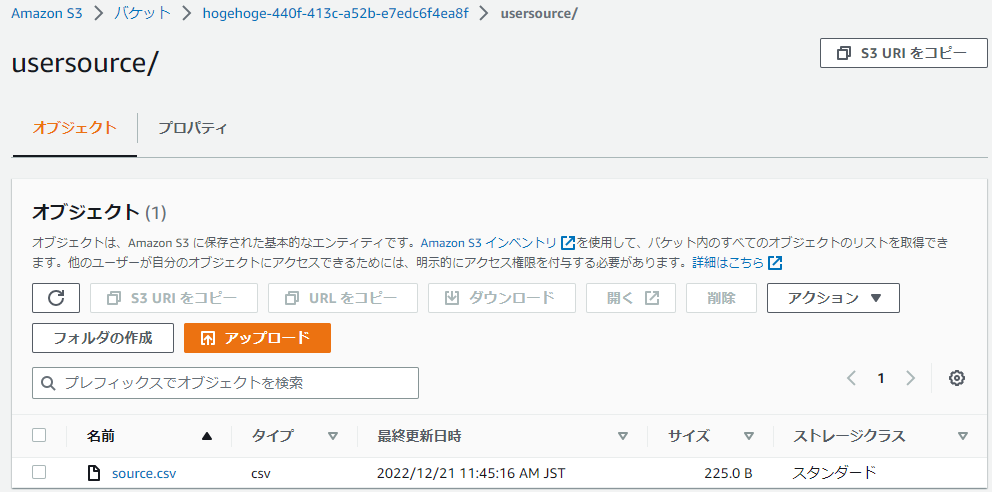
ソースデータの配置
- S3バケット:
hogehoge-440f-413c-a52b-e7edc6f4ea8f - データ配置先:
/usersource/source.csv
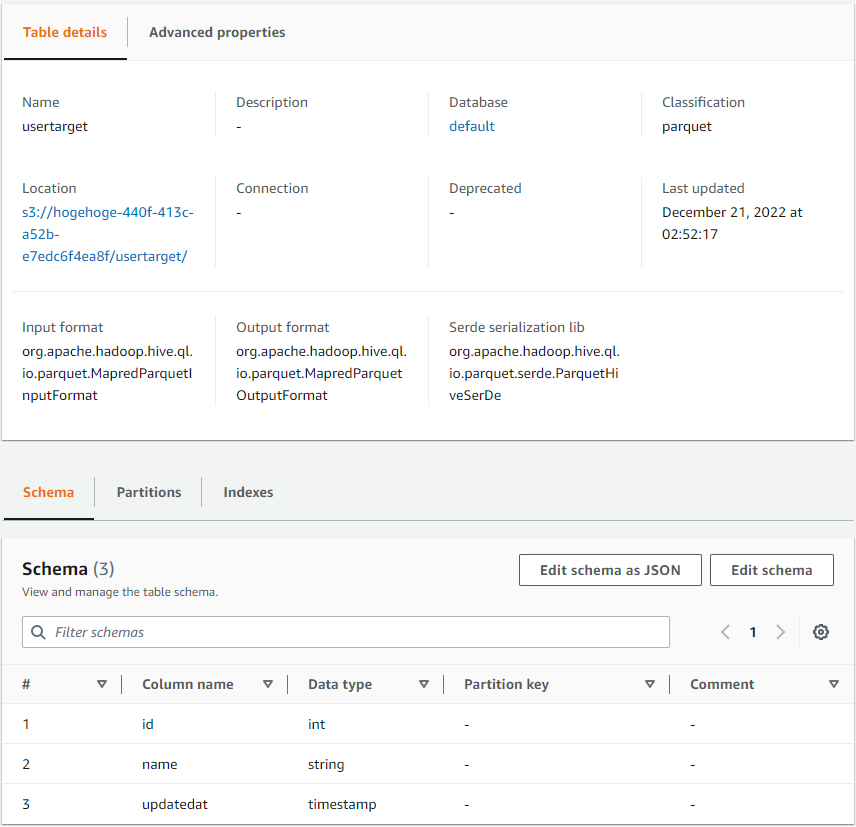
出力先Glueテーブルの作成
- データベース:
default - テーブル名:
usertarget - データストア:
s3://hogehoge-440f-413c-a52b-e7edc6f4ea8f/usertarget/ - データフォーマット:
Parquet - カラム:
id(int)name(string)updatedat(timestamp)
- パーティション:なし
AWS Glue StudioでのGlueジョブの作成
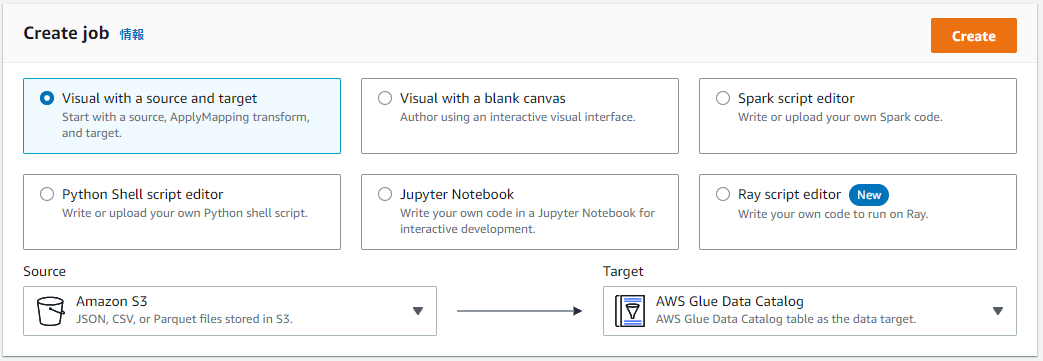
まずはCreate Jobのセクションでジョブを作成します。
- ジョブタイプ:Visual with a source and target
- Source:Amazon S3
- Target:AWS Glue Data Catalog
ジョブ編集画面に遷移し、左側には処理のグラフが現れます。
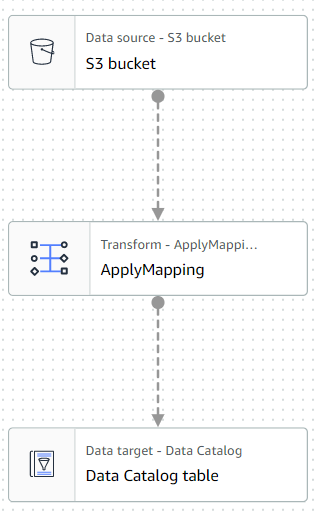
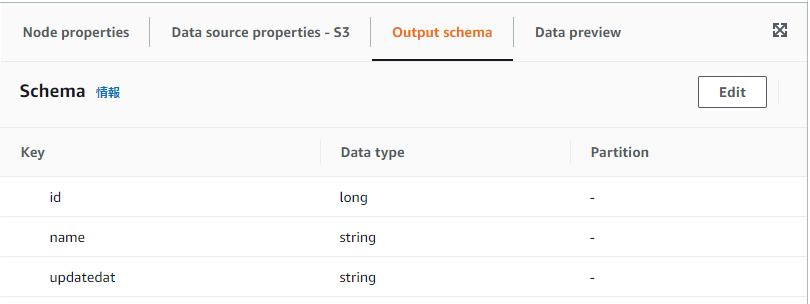
グラフ上の「S3 bucket」ノードをクリックし、各種設定を実施します。
- Data source propertiesタブ
- S3 source type:S3 location
- S3 URL:
s3://hogehoge-440f-413c-a52b-e7edc6f4ea8f/usersource/ - Data format:CSV
- First line of source file contains column headers:チェックする
- Output schemaタブ
- idの列が勝手にlongで認識されているのでstringに修正
グラフ上の「ApplyMapping」ノードをクリックし、各種設定を実施します。
- Transformタブ
id→id(int)name→name(string)updatedat→updatedat(timestamp)
グラフ上の「Data Catalog table」ノードをクリックし、各種設定を実施します。
- Data target propertiesタブ
- Database:
default - Table:
usertarget
- Database:
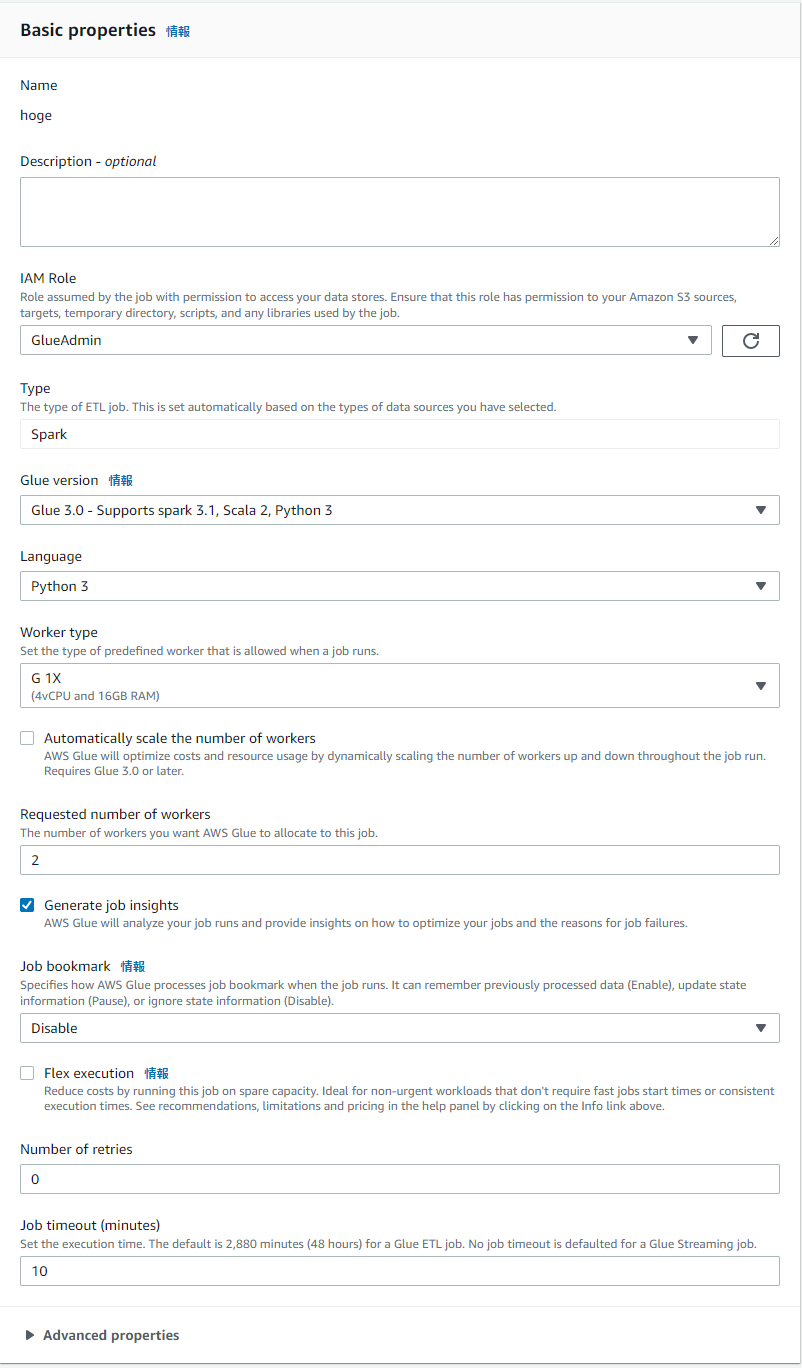
ジョブそのものを設定します。 (Job detailsタブ)
- Basic Properties
- Name:適当に設定してください
- IAM role:設定する (今回の手順には含めていませんが、あったものを使いました)
- workers:2
- Job bookmark:Disable
- retries:0
- timeout:10 (minutes)
- Advanced Properties
- Script filename:job.py

最後に忘れずにSaveを押して保存しましょう。
ジョブを実行する
実際にジョブを実行してみます。特にコーディングもせず、マネジメントコンソールのフォームに従っているだけなので、ジョブも問題なく終了しました。
結果の確認
Athenaでクエリしてみる
出来上がったデータをAthenaからクエリしてみました。
が、事前調査の通り、updatedat列のtimestampがうまく認識されていないようです。
|
1 |
SELECT * FROM default.usertarget |
|
1 2 3 4 5 |
"id","name","updatedat" "1","すごい たろう", "2","ものすごい じろう", "3","とんでもない さぶろう", "5","はんぱない ごろう", |
SQL Query変換で日付文字列を認識させてみる
スラッシュ区切りの日付をtimestampとして認識させるために、先ほどのジョブをちょっといじります。
ApplyMapingノードの変更
下記の部分を変更していきます。
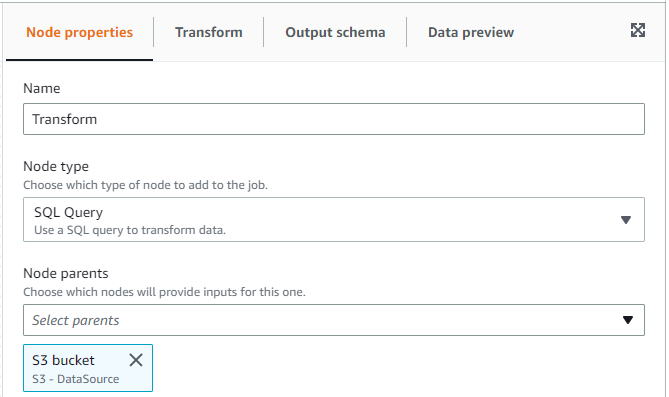
- Node Propertiesタブ
- Name:Transform
- Node type:SQL Query
- Node parents:S3bucket (そのまま)
- Transformタブ
- Input sources
- S3bucket:
myDataSource
- S3bucket:
- SQL Query:
SELECT
CAST(id AS INT) AS id,
name AS name,
to_timestamp(updatedat, 'yyyy/MM/dd HH:mm:ss') AS updatedat
FROM
myDataSource
- Input sources
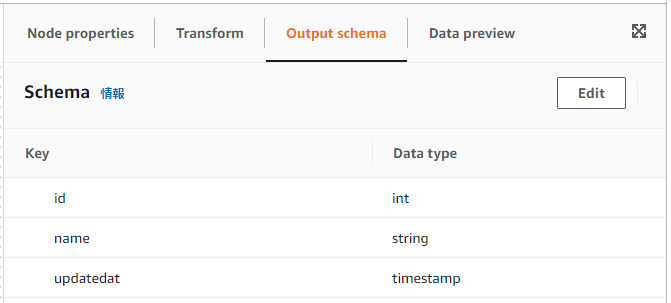
- Output schemaタブ
id:intname:stringupdatedat:timestamp
ジョブを再実行する
ジョブ実行の前に、出力先(今回の場合はs3://hogehoge-440f-413c-a52b-e7edc6f4ea8f/usertarget/)に存在する、前のジョブの出力であるparquetファイルを削除しておきます。
ファイルの削除が終わったら、改めてジョブを実行します。
今回はSQL Queryの部分に限ってはコードを投入していますが、それ以外は前のジョブと同じですね。最初のジョブより多少時間がかかった印象はありますが、無事に実行されました。
結果の再確認
出来上がったデータをAthenaからクエリしてみました。
前とは違い、日時の文字列が正しくtimestamp型としてクエリ出来ています。
|
1 |
SELECT * FROM default.usertarget |
|
1 2 3 4 5 |
"id","name","updatedat" "1","すごい たろう","2020-01-15 03:44:40.000" "2","ものすごい じろう","2022-10-12 05:12:59.000" "3","とんでもない さぶろう","2022-03-15 12:34:56.000" "5","はんぱない ごろう","2021-10-29 23:55:10.000" |
まとめ
ApplyMapping変換では対応できない日時形式の場合に使える手法の一つとして、SQL Query変換によるカスタム日付形式の認識方法をご紹介しました。
変換には他にもいろいろ用意されていますし、複数の入力をマージして変換を書けることもできますので、みなさんもぜひ試してみてください。
投稿者プロフィール
- 根っこはインフラ屋な古いおじさん。
最新の投稿
 AWS2025年12月4日CloudFormationのドリフト認識変更セットを使ってみた(続編)
AWS2025年12月4日CloudFormationのドリフト認識変更セットを使ってみた(続編)- AWS2025年11月27日CloudFormationのドリフト認識変更セットを使ってみた
 AWS2025年11月21日【短篇】AWSバックアップのタグによるリソース割り当てで軽くはまった
AWS2025年11月21日【短篇】AWSバックアップのタグによるリソース割り当てで軽くはまった AWS2025年11月17日ALBでトラストストアを使ってみた
AWS2025年11月17日ALBでトラストストアを使ってみた