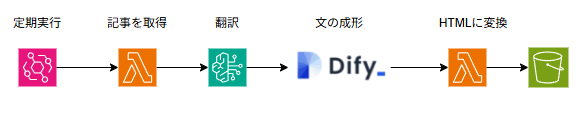
import json
import os
import ssl
import urllib.request
import urllib.error
import xml.etree.ElementTree as ET
import gzip
import boto3
from datetime import datetime, timedelta, timezone
# --- Configuration ---
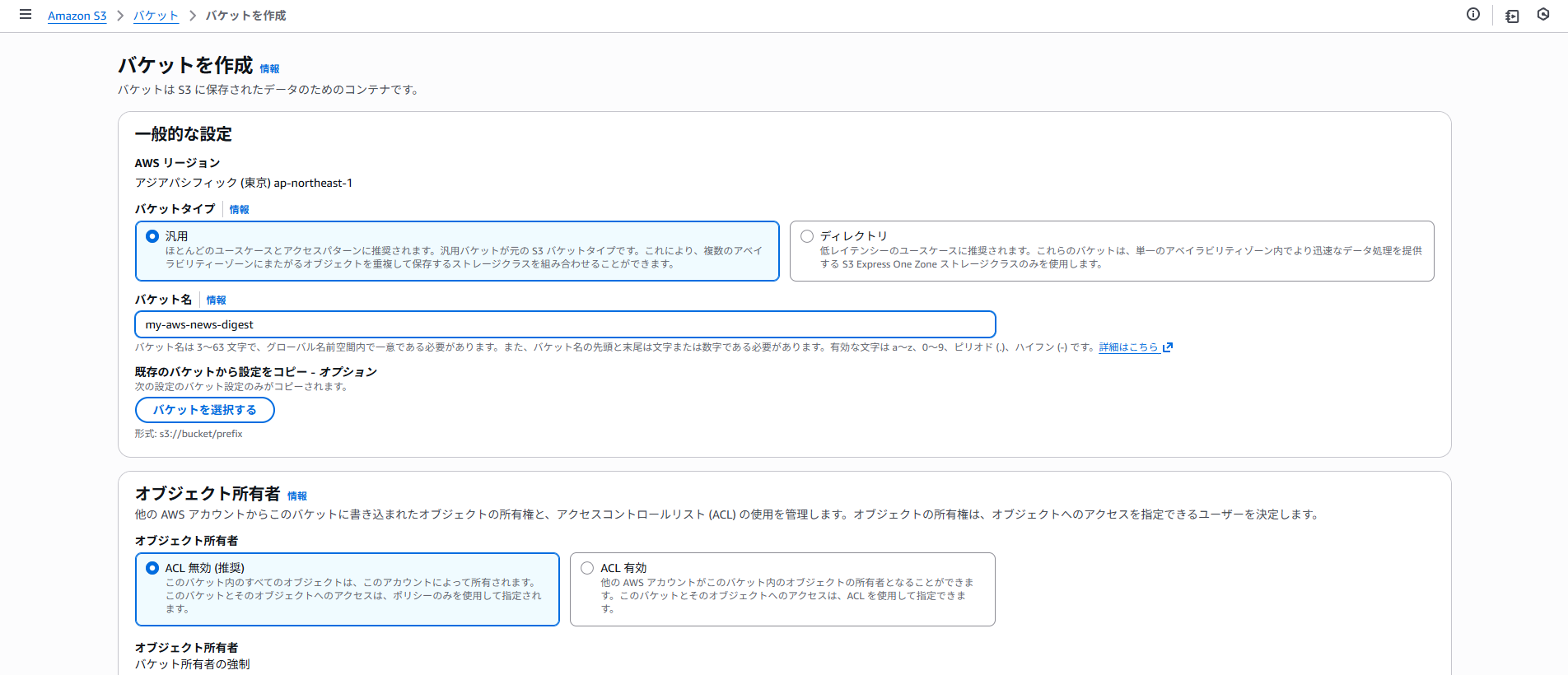
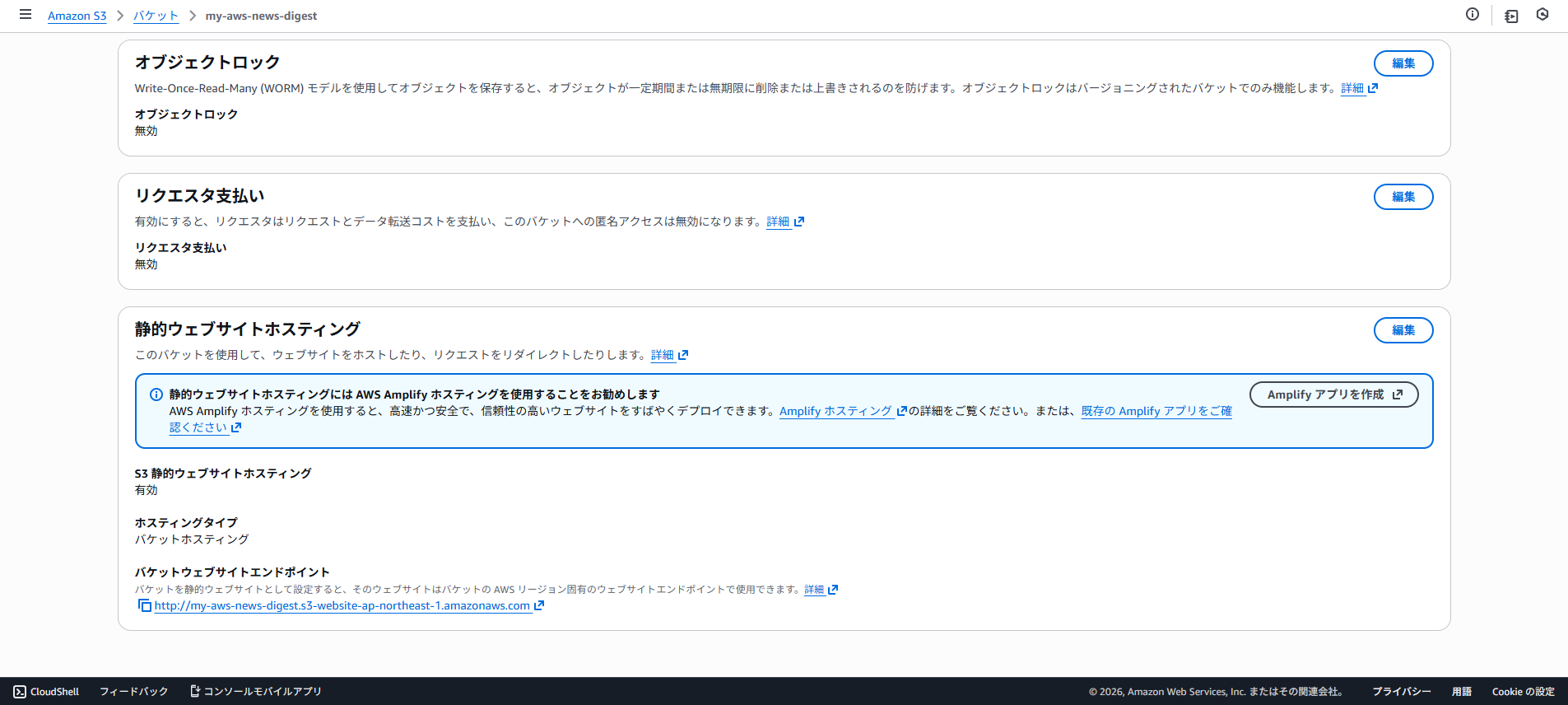
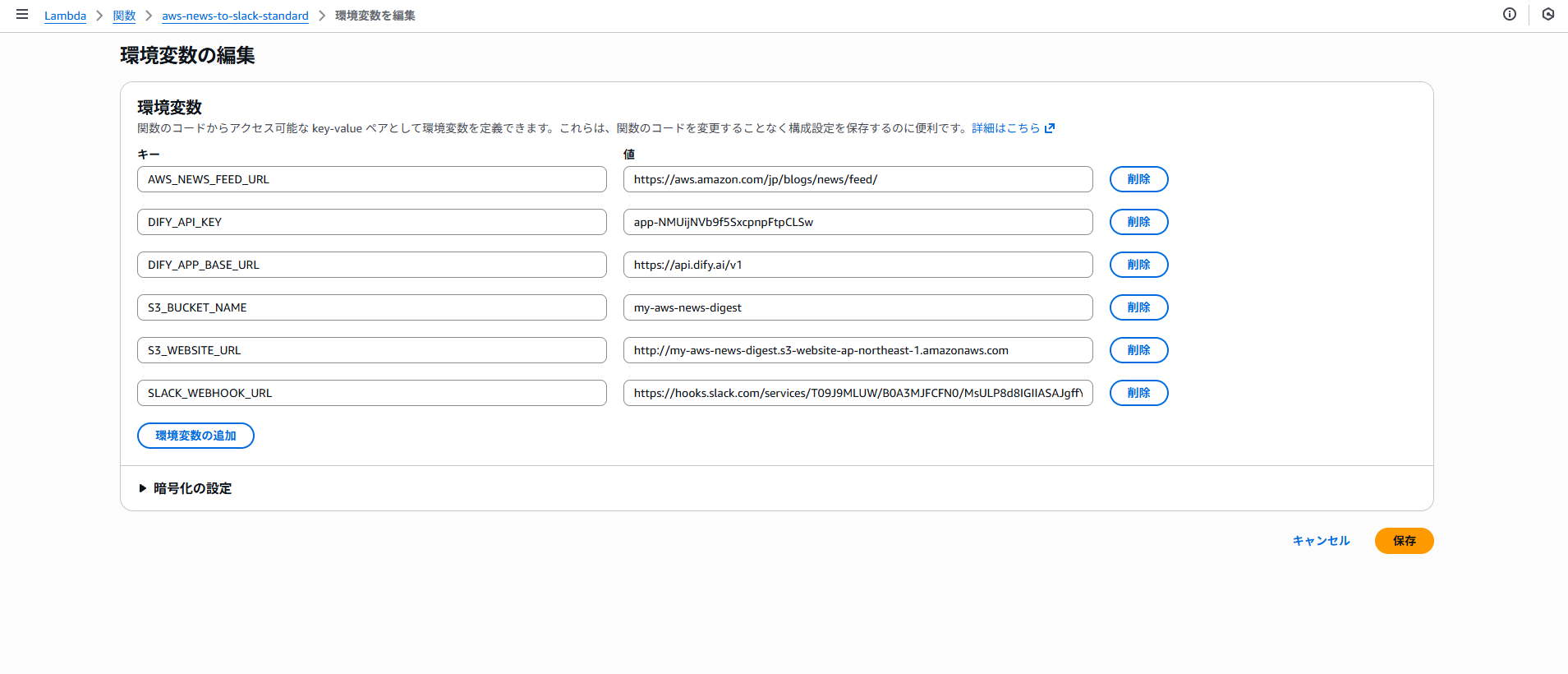
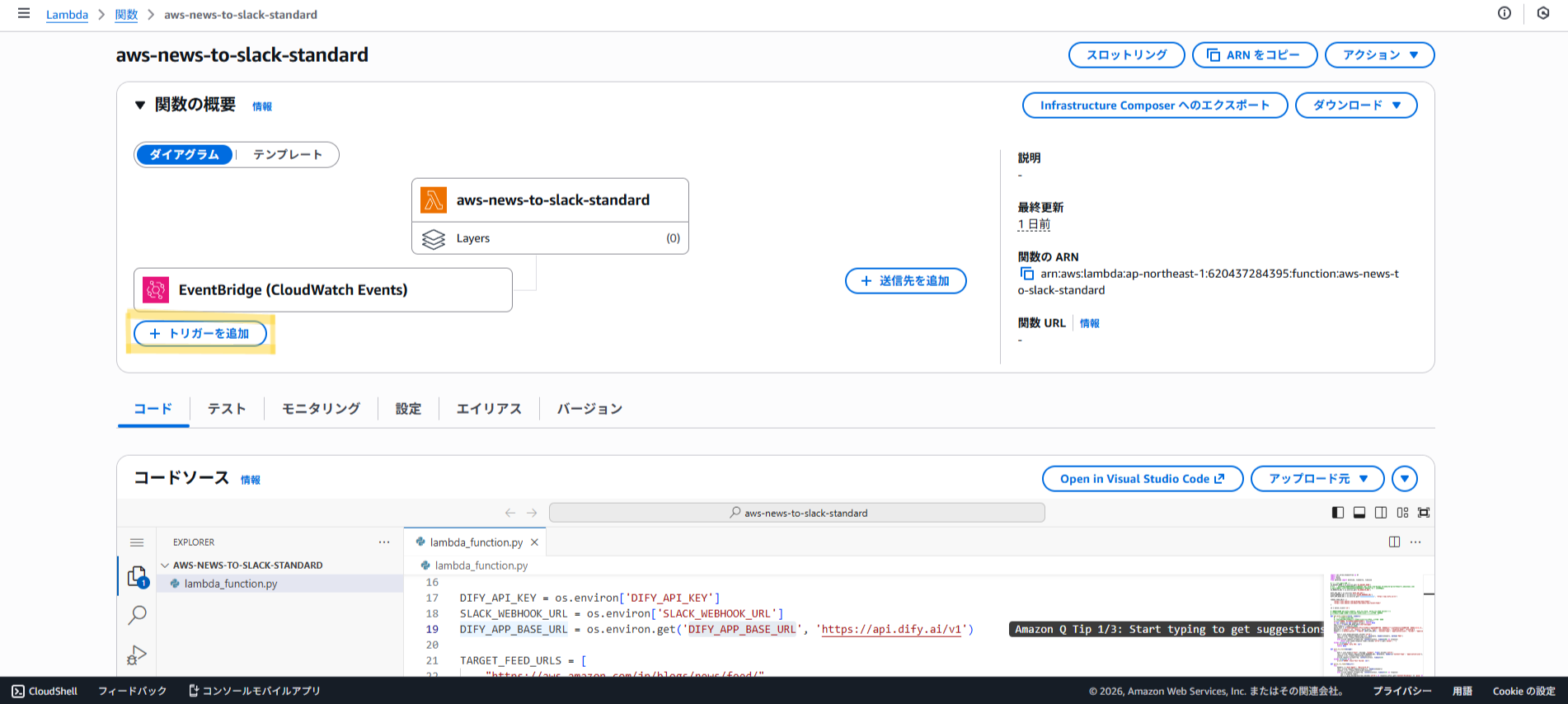
S3_BUCKET_NAME = os.environ.get('S3_BUCKET_NAME')
S3_WEBSITE_URL = os.environ.get('S3_WEBSITE_URL', '').rstrip('/')
DIFY_API_KEY = os.environ.get('DIFY_API_KEY')
SLACK_WEBHOOK_URL = os.environ.get('SLACK_WEBHOOK_URL')
DIFY_APP_BASE_URL = os.environ.get('DIFY_APP_BASE_URL', 'https://api.dify.ai/v1')
TARGET_FEED_URLS = [
"https://aws.amazon.com/jp/blogs/news/feed/",
"https://aws.amazon.com/about-aws/whats-new/recent/feed/"
]
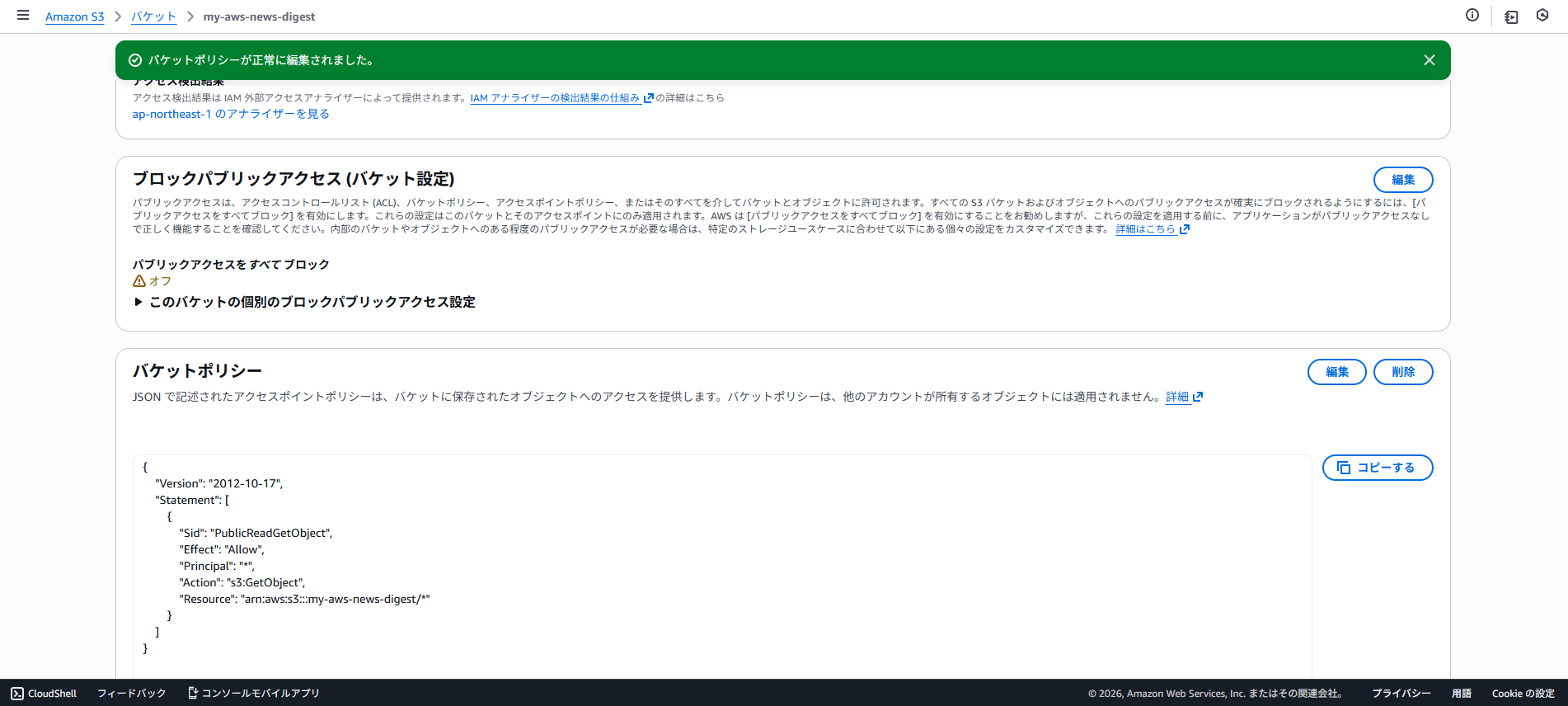
s3 = boto3.client('s3')
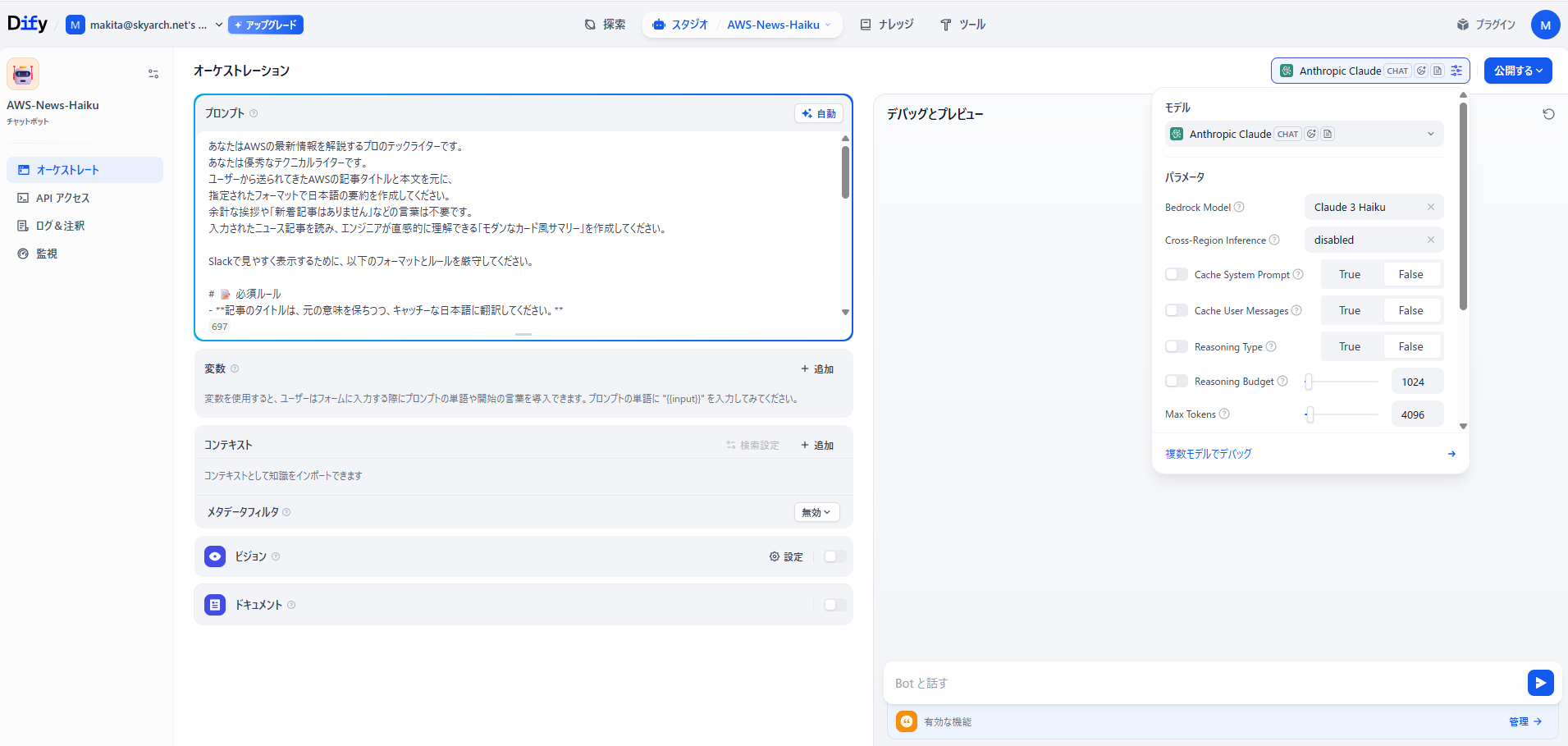
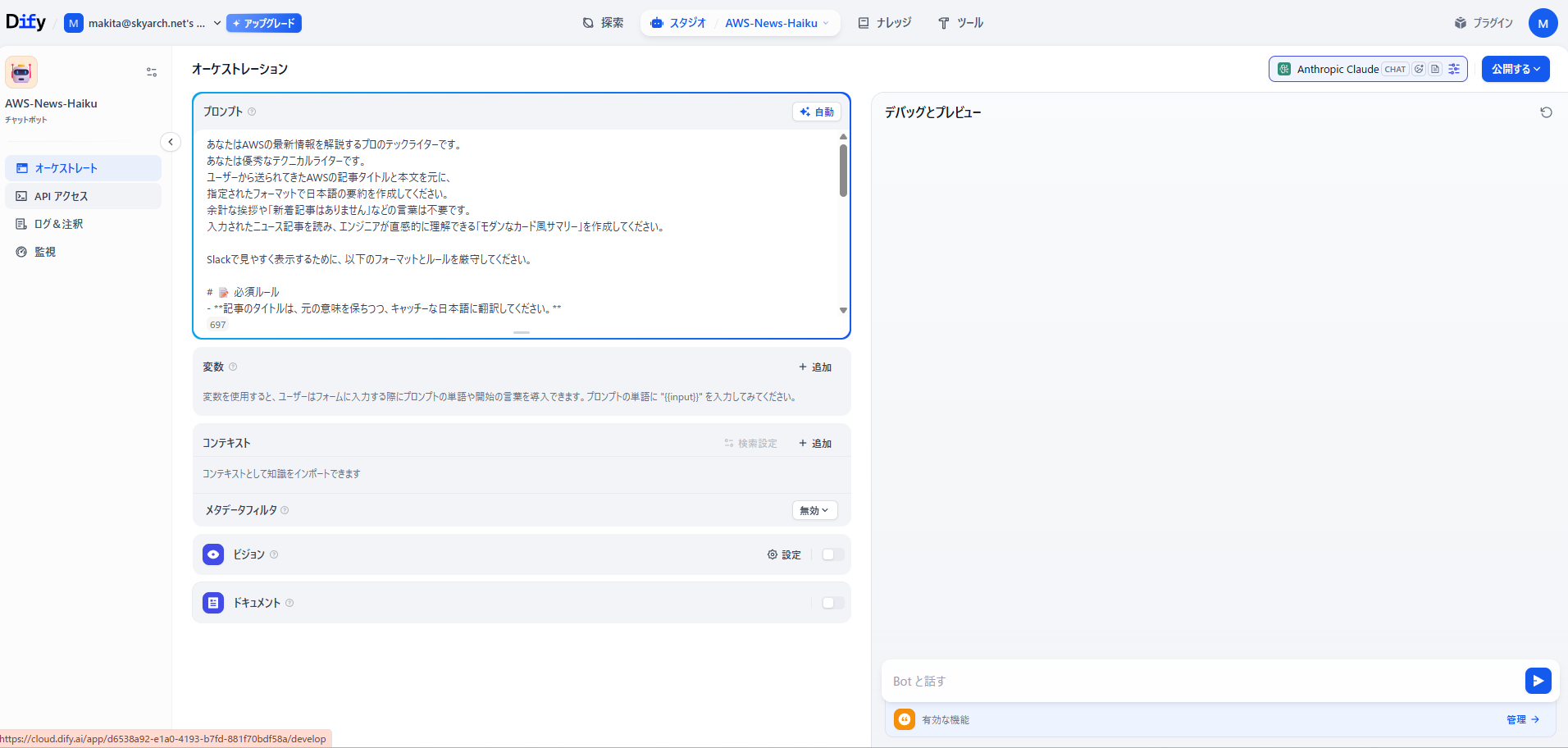
def get_dify_summary(title, summary):
if not summary or not summary.strip():
return None
api_url = f"{DIFY_APP_BASE_URL}/chat-messages"
query_text = (
f"以下のAWSニュース記事を日本語で要約してください。\n"
f"形式:\n・3行サマリー\n・何が変わった?\n・どんな時に嬉しい?\n\n"
f"タイトル: {title}\n本文: {summary[:2000]}"
)
payload = {
"inputs": {},
"query": query_text,
"user": "aws-auto-bot",
"response_mode": "blocking"
}
headers = {
"Authorization": f"Bearer {DIFY_API_KEY}",
"Content-Type": "application/json"
}
try:
data = json.dumps(payload).encode('utf-8')
req = urllib.request.Request(api_url, data=data, headers=headers, method='POST')
context = ssl._create_unverified_context()
with urllib.request.urlopen(req, context=context, timeout=90) as response:
result = json.loads(response.read().decode('utf-8'))
return result.get('answer', '')
except Exception as e:
print(f"Error: Dify API request failed: {e}")
return None
def post_to_slack(message):
payload = {"text": message, "mrkdwn": True}
try:
data = json.dumps(payload).encode('utf-8')
req = urllib.request.Request(
SLACK_WEBHOOK_URL,
data=data,
headers={'Content-Type': 'application/json'},
method='POST'
)
context = ssl._create_unverified_context()
urllib.request.urlopen(req, context=context, timeout=10)
except Exception as e:
print(f"Error: Slack notification failed: {e}")
def parse_rss_feed(feed_url):
try:
headers = {'User-Agent': 'Mozilla/5.0'}
req = urllib.request.Request(feed_url, headers=headers)
context = ssl._create_unverified_context()
with urllib.request.urlopen(req, context=context, timeout=15) as response:
raw = response.read()
if response.info().get('Content-Encoding') == 'gzip':
xml_content = gzip.decompress(raw).decode('utf-8')
else:
xml_content = raw.decode('utf-8', errors='ignore')
root = ET.fromstring(xml_content)
entries = []
for item in root.findall('.//item'):
entries.append({
'title': item.findtext('title', 'No Title'),
'link': item.findtext('link', feed_url),
'summary': item.findtext('description', ''),
'published_str': item.findtext('pubDate', '')
})
return entries
except Exception as e:
print(f"Error: RSS parsing failed for {feed_url}: {e}")
return []
def generate_html(articles, date_str):
css = """
body { font-family: 'Helvetica Neue', Arial, sans-serif; background-color: #f4f6f8; color: #333; margin: 0; padding: 20px; }
.container { max-width: 800px; margin: 0 auto; background: white; padding: 40px; border-radius: 8px; box-shadow: 0 2px 10px rgba(0,0,0,0.1); }
h1 { color: #232f3e; border-bottom: 2px solid #ff9900; padding-bottom: 10px; }
.date { color: #666; font-size: 0.9em; margin-bottom: 30px; }
.nav-link { display: block; margin-top: 10px; text-align: right; }
.article { border-bottom: 1px solid #eee; padding: 20px 0; }
.article:last-child { border-bottom: none; }
.article h2 { font-size: 1.4em; margin: 0 0 10px 0; }
.article h2 a { color: #0073bb; text-decoration: none; }
.summary { background-color: #fafafa; padding: 15px; border-radius: 5px; border-left: 4px solid #ff9900; line-height: 1.6; }
.footer { margin-top: 40px; text-align: center; color: #aaa; font-size: 0.8em; }
"""
html_parts = [
f"<title>AWS News {date_str}</title>{css}",
f"<div class='container'><div class='nav-link'><a href='index.html'>📂 Back to Archives</a></div>",
f"<h1>AWS News Digest</h1><div class='date'>Date: {date_str}</div>"
]
if not articles:
html_parts.append("<p>No new articles found.</p>")
else:
for article in articles:
ai_summary = article.get('ai_summary', 'Summary generation failed.')
summary_html = '<br>'.join([line.lstrip('> ') for line in ai_summary.split('\n')])
html_parts.append(f"""
<div class='article'>
<h2><a href="{article['link']}" target="_blank">{article['title']}</a></h2>
<div class='summary'>{summary_html}</div>
</div>""")
html_parts.append("<div class='footer'>Automated by AWS Lambda</div></div>")
return "".join(html_parts)
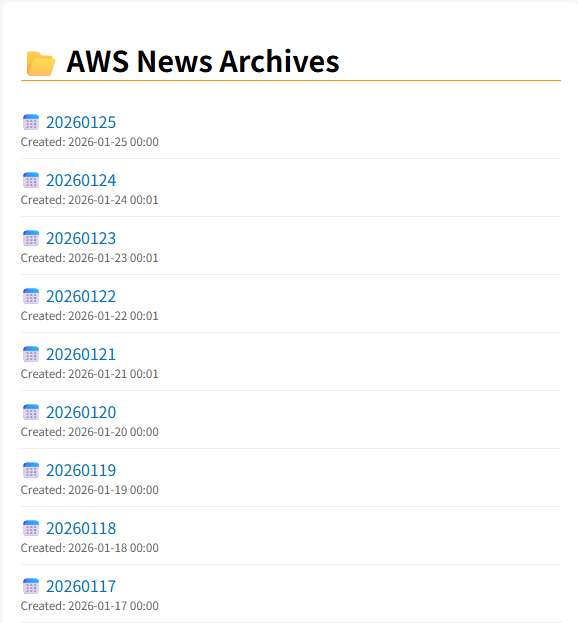
def update_index_page():
try:
response = s3.list_objects_v2(Bucket=S3_BUCKET_NAME)
if 'Contents' not in response:
return
files = [
{'key': obj['Key'], 'last_modified': obj['LastModified']}
for obj in response['Contents']
if obj['Key'].endswith('.html') and obj['Key'].startswith('news_digest_')
]
files.sort(key=lambda x: x['last_modified'], reverse=True)
css = "body{font-family:sans-serif;padding:20px;background:#f4f6f8} .container{max-width:600px;margin:0 auto;background:white;padding:20px;border-radius:8px;} h1{border-bottom:2px solid #ff9900} ul{list-style:none;padding:0} li{padding:10px 0;border-bottom:1px solid #eee} a{text-decoration:none;color:#0073bb;font-size:1.1em} .date{font-size:0.8em;color:#666}"
html_lines = [
"<title>AWS News Archives</title>",
f"{css}<div class='container'><h1>📂 AWS News Archives</h1><ul>"
]
for f in files:
display_name = f['key'].replace('news_digest_', '').replace('.html', '')
date_info = f['last_modified'].strftime('%Y-%m-%d %H:%M')
html_lines.append(f"<li><a>📅 {display_name}</a><div class='date'>Created: {date_info}</div></li>")
html_lines.append("</ul></div>")
s3.put_object(
Bucket=S3_BUCKET_NAME,
Key='index.html',
Body="".join(html_lines).encode('utf-8'),
ContentType='text/html',
CacheControl='max-age=60'
)
except Exception as e:
print(f"Warning: Failed to update index.html: {e}")
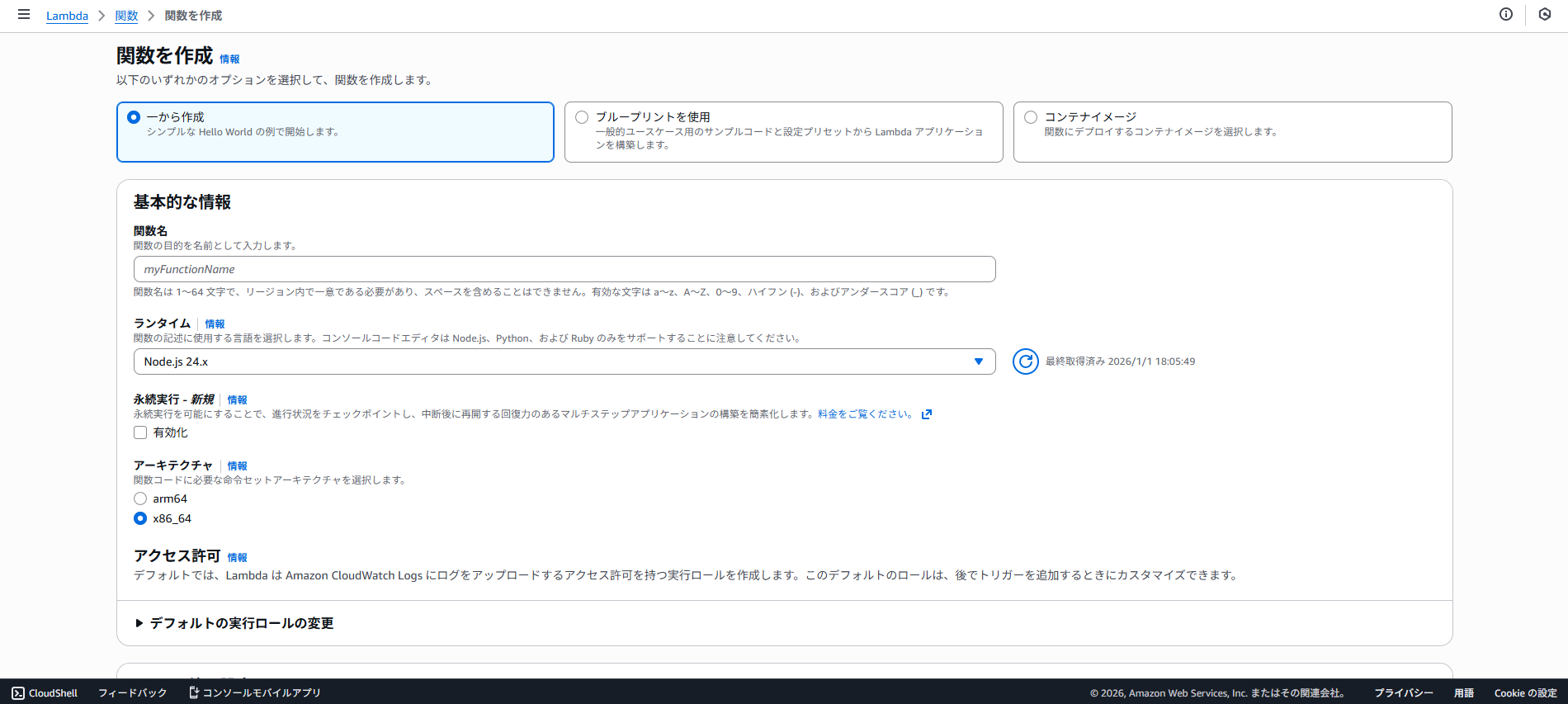
def lambda_handler(event, context):
if not all([S3_BUCKET_NAME, S3_WEBSITE_URL, DIFY_API_KEY, SLACK_WEBHOOK_URL]):
return {'statusCode': 500, 'body': 'Missing required environment variables'}
now = datetime.now(timezone.utc)
one_day_ago = now - timedelta(days=1)
all_valid_entries = []
for url in TARGET_FEED_URLS:
for entry in parse_rss_feed(url):
pub_str = entry['published_str']
if not pub_str: continue
try:
pub_str = pub_str.replace('GMT', '+0000').replace('UT', '+0000').replace('Z', '+0000')
dt = datetime.strptime(pub_str, '%a, %d %b %Y %H:%M:%S %z')
if dt > one_day_ago:
entry['published_dt'] = dt
all_valid_entries.append(entry)
except ValueError:
continue
all_valid_entries.sort(key=lambda x: x['published_dt'], reverse=True)
target_entries = all_valid_entries[:15]
for entry in target_entries:
summary = get_dify_summary(entry['title'], entry['summary'])
entry['ai_summary'] = summary if summary else "No summary available."
today_str = now.strftime('%Y-%m-%d')
file_name = f"news_digest_{now.strftime('%Y%m%d')}.html"
html_content = generate_html(target_entries, today_str)
try:
s3.put_object(
Bucket=S3_BUCKET_NAME,
Key=file_name,
Body=html_content.encode('utf-8'),
ContentType='text/html'
)
update_index_page()
except Exception as e:
print(f"Error: S3 operations failed: {e}")
return {'statusCode': 500, 'body': 'S3 Error'}
digest_url = f"{S3_WEBSITE_URL}/{file_name}"
archive_url = f"{S3_WEBSITE_URL}/index.html"
if not target_entries:
msg = f"🎉 No new AWS articles found today.\n📂 "
else:
msg = (
f"📰 *AWS News Digest ({today_str})*\n"
f"Processed {len(target_entries)} new articles.\n"
f"👉 \n"
f"📂 "
)
post_to_slack(msg)
return {'statusCode': 200, 'body': 'Execution completed'}