はじめに
Amazon Bedrockに触れてみよう!の第二弾として、簡単にRAG機能が構築出来る「Knowledge Base for Amazon Bedrock」についてご紹介させて頂きます。
第一弾ブログはこちら -> Amazon Bedrockと触れ合おう
目次
Knowledge Base for Amazon Bedrockとは?
RAGとは
RAG(Retrieval Augmented Generation)は、大規模なデータベースや文書を検索し、それらの情報を活用して回答や文書を生成する技術です。
提供される基盤モデルは、通常、学習時の訓練データに基づいていますが、RAGを使用することで、実際のデータや文書に基づいた情報を取り入れることができます。
これにより、モデルの回答や生成物の質が向上するという利点があります。
Knowledge Base for Amazon Bedrockとは
これまで困難とされていたRAG構築が、Knowledge Base for Amazon Bedrock(以下、Knowledge Base)のGAにより数クリック程度で簡単に構築出来るようになりました。
Knowledge Baseの構成図はこのようなイメージとなります。
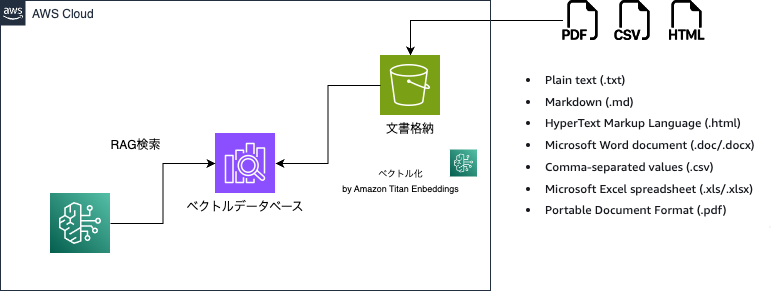
使い方としては下記の流れとなります。
- S3にRAGに読み込ませたい文書を格納します。対応してる拡張子はこちらに記載されています。
- Amazon Titan Embeddingsによりベクトル化され、ベクトルデータベースに保存
- 専用のAPIを通じて、リクエストを投げる
では実際にRAG構築をしてみましょう!
実際に作成してみよう
2023/12時点では、Knowledge Baseはバージニア北部/オレゴンのみ対応している機能となります。
- バージニア北部を選択し、Bedrockのコンソール画面より Orchestration -> Knowledge base -> Create knowledge base の順番で構築を進めます。
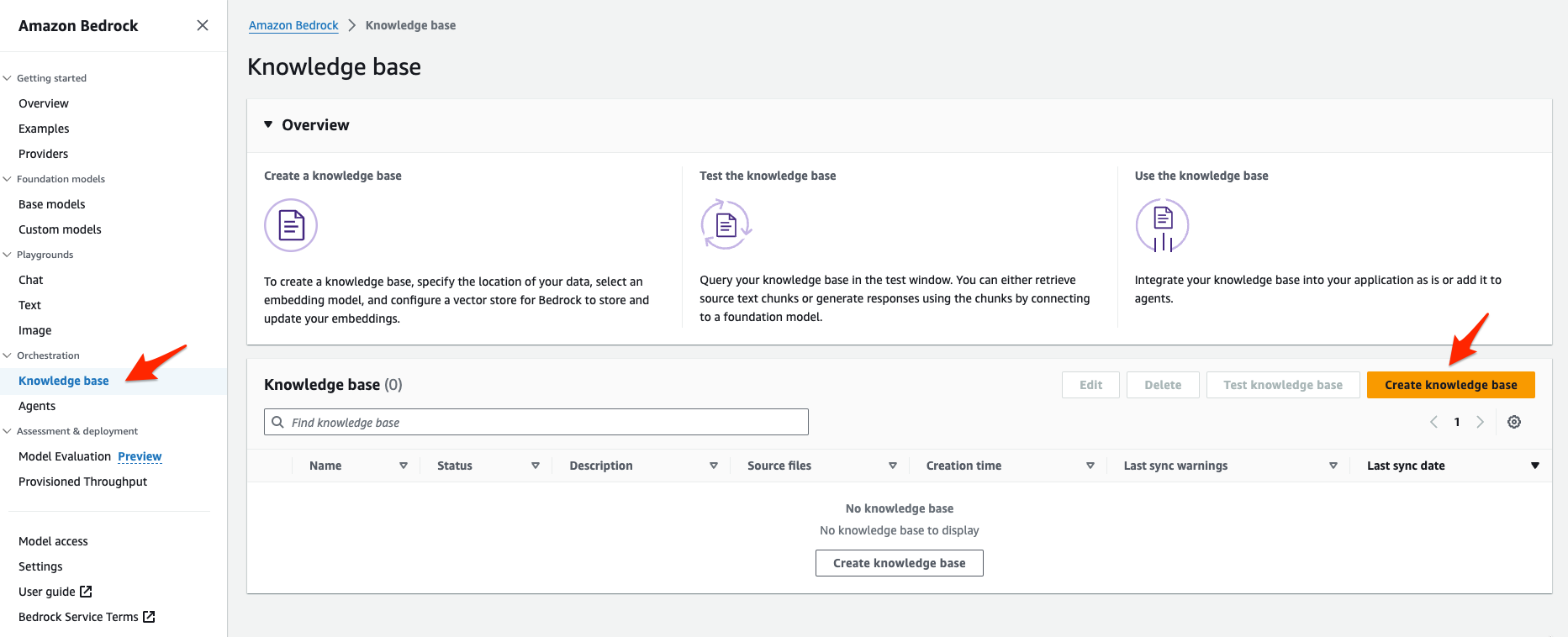
-
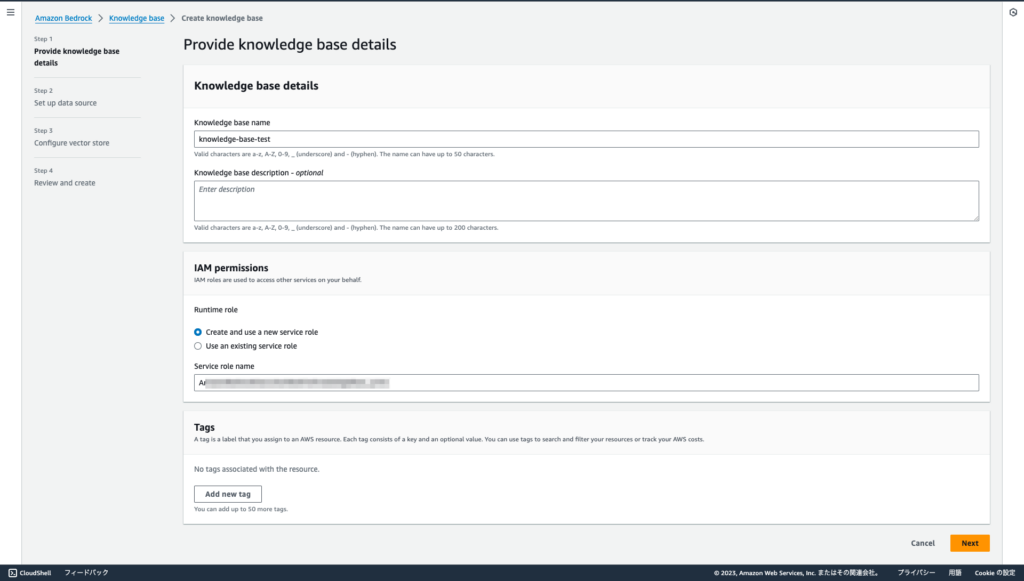
Step1 Provide knowledge base details
Knowledge Baseの名称やIAMロール、タグの設定を行います。
IAMロールは必要最低限のポリシーのを自動的に作成してくれるため、「Create and use a new service role」を選択しました。
-
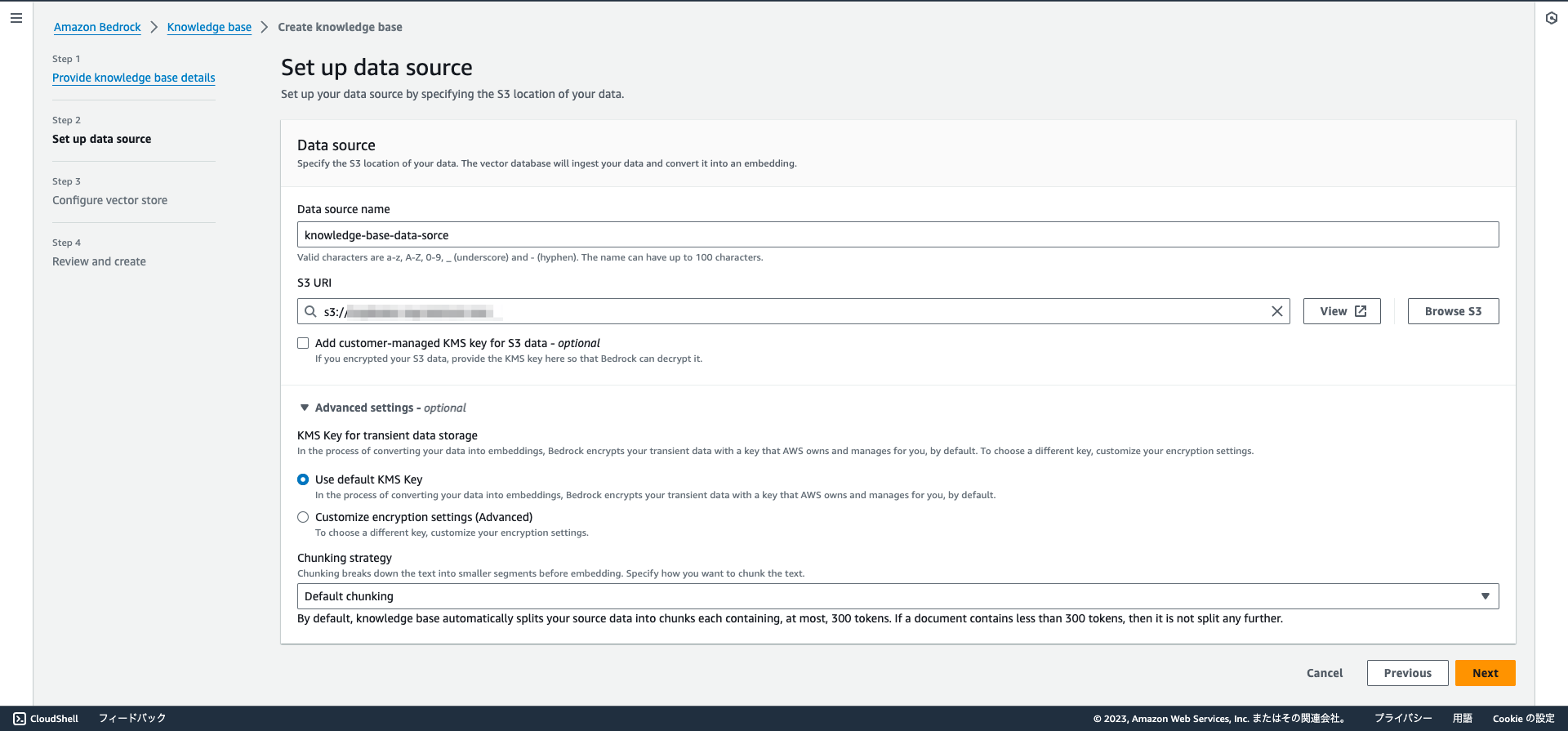
Step 2 Set up data source
次にデータソースを設定します。
Kendraと異なり、Webクローラー等の設定はできないためS3のみがデータソースの対象となります。
同一リージョンに事前に作成していたS3バケットを選択し、KMS KeyはDefaultを選択します。
Chunking strategyはテキストの分割方法になりますが、値を変えることでどう結果が異なってくるか不明のため一旦はDefaultを選択します。
-
Step 3 Configure vector store
次にベクトルストアを設定します。
ドキュメントをベクトル化するモデル(Embeddings model)ですが、現在は Amazon Titan Embeddings G1 - Text v1.2のみが対応となるようです。
またベクトルデータベースですが、現在は下記4つが対応しております。
・Amazon OpenSearch Serverless(推奨)
・Amazon Aurora PostgreSQL(2023/12/21のUpdateで追加)
・Pinecone(AWS外サービス)
・Redis Enterprise Cloud(AWS外サービス)
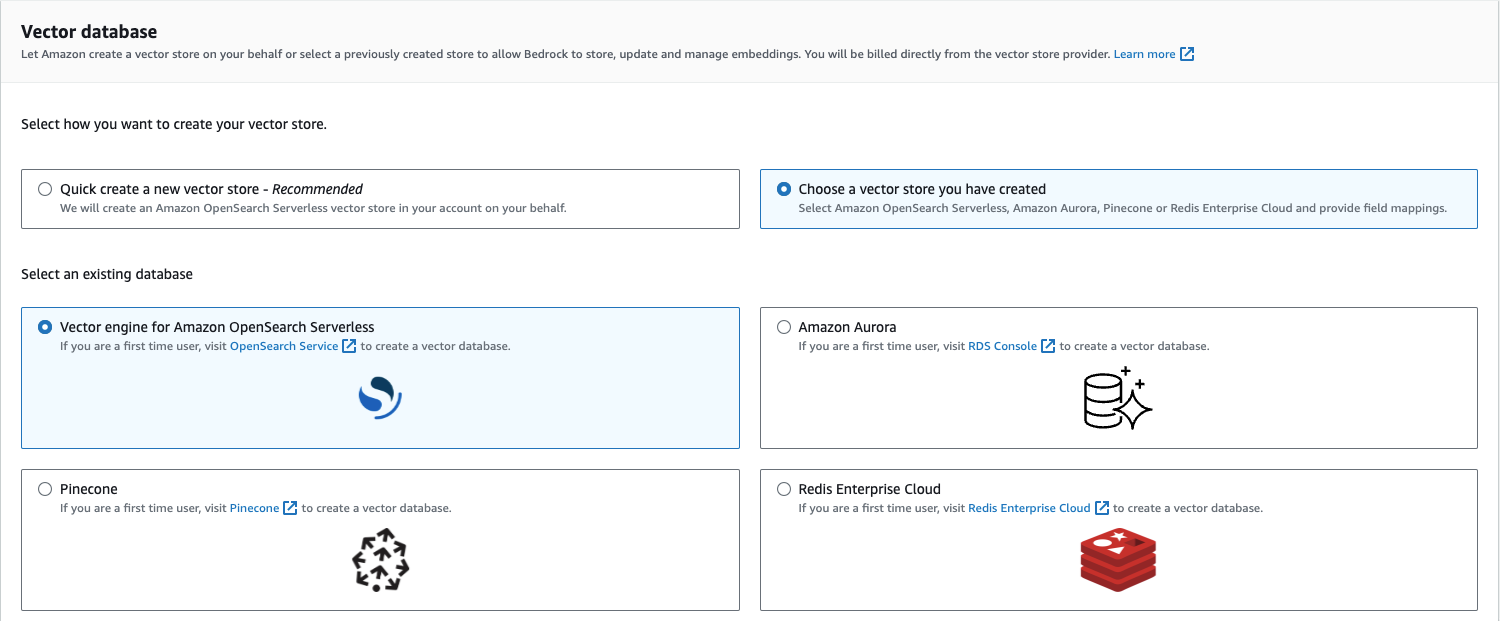
本ブログでは推奨とされるAmazon OpenSearch Serverlessを選択します。
Amazon OpenSearch Serverless自体の構築も裏側で行ってくれます。便利ですなぁ
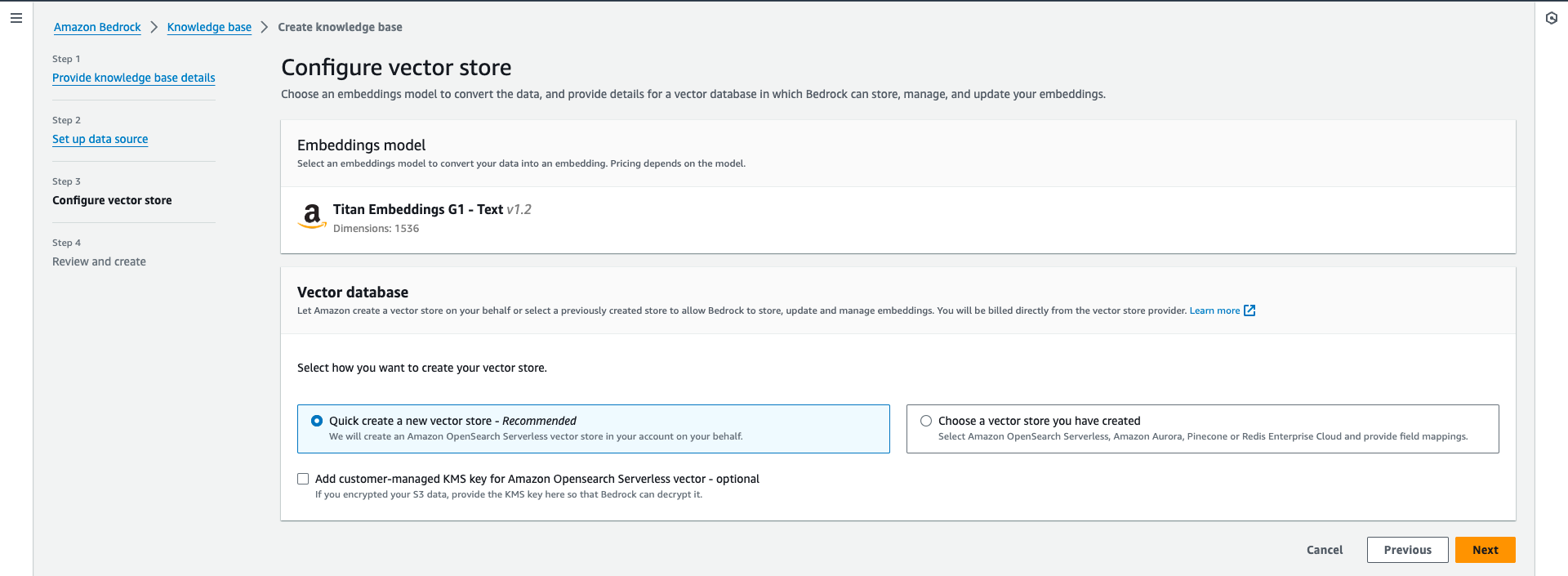
最後に確認画面で内容を確認し、Create knowledge baseでRAGが作成されるのを待ちます。
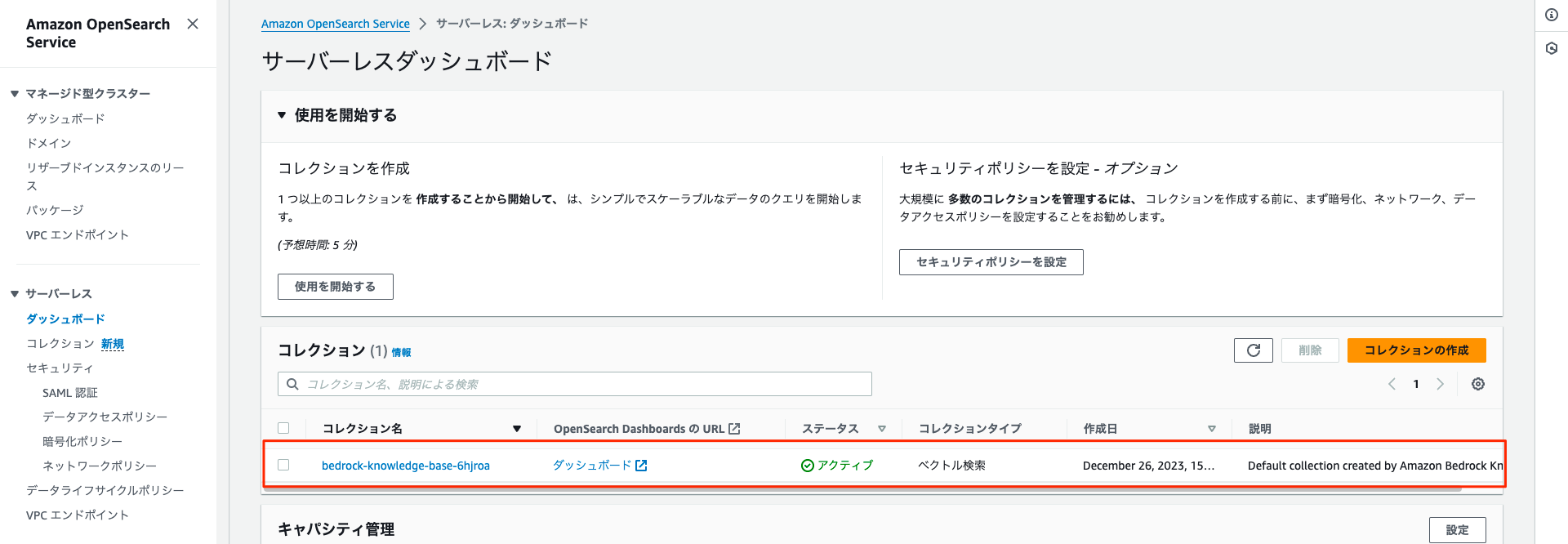
Amazon OpenSearch Serveiceのサーバレスに作成されていることが確認出来ます。
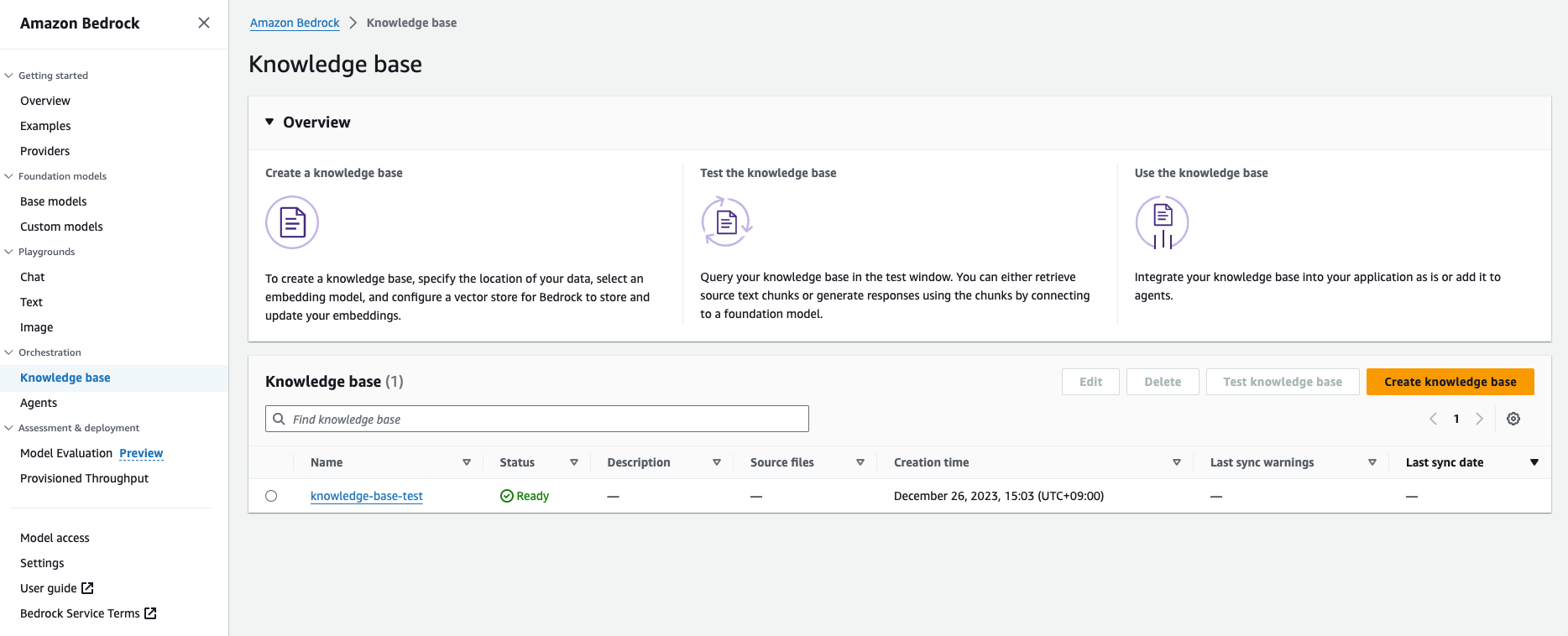
Knowledge Baseの一覧画面からもRAGが作成されたことが確認出来ます。
Knowledge Baseの画面から作成が完了すると自動的にこのような画面が表示されます。
筆者は事前に対象バケットに文書をアップロードしていますので、Syncを押下してベクトル化を実行させます。
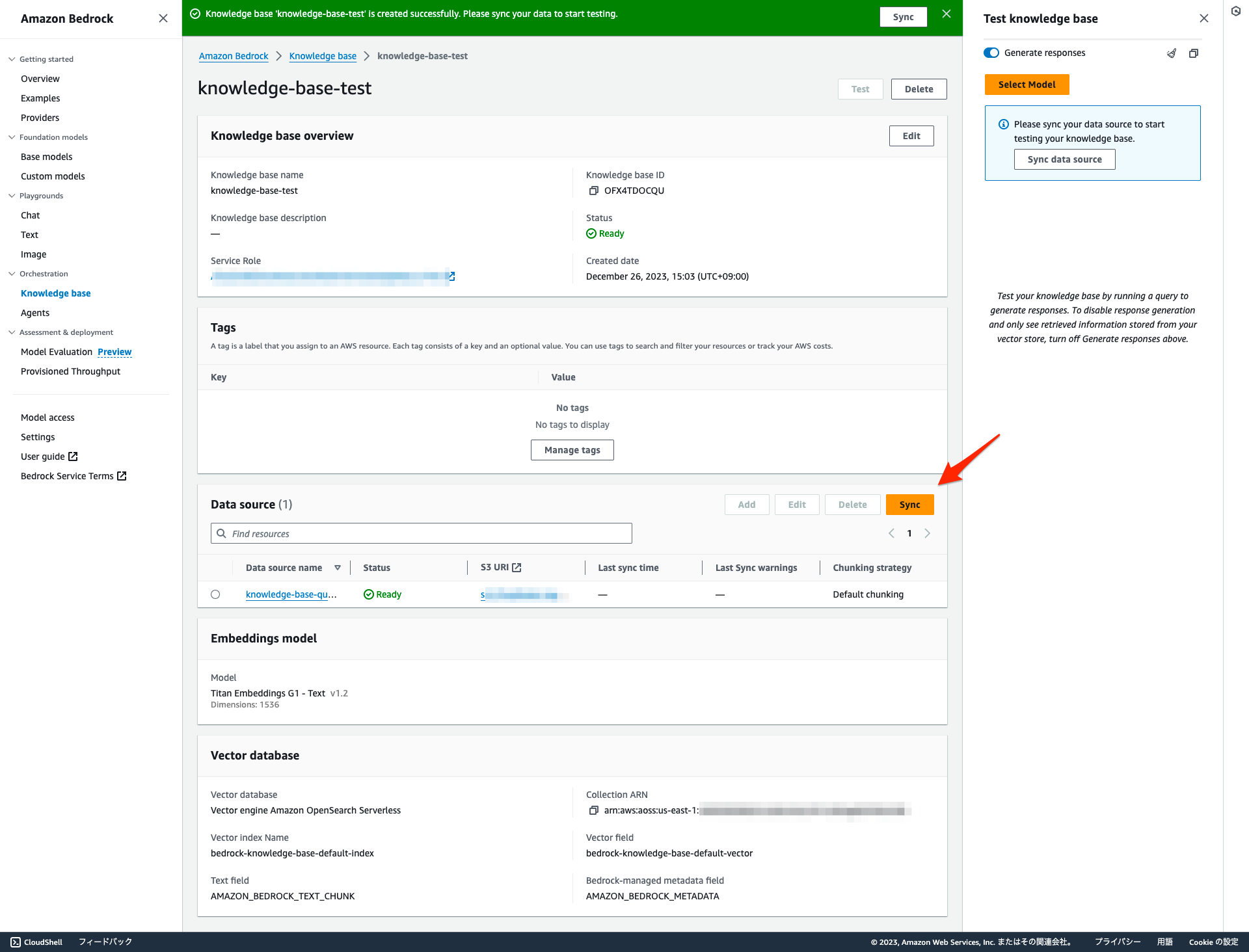
Syncが完了すると、Last sync timeに反映されます。
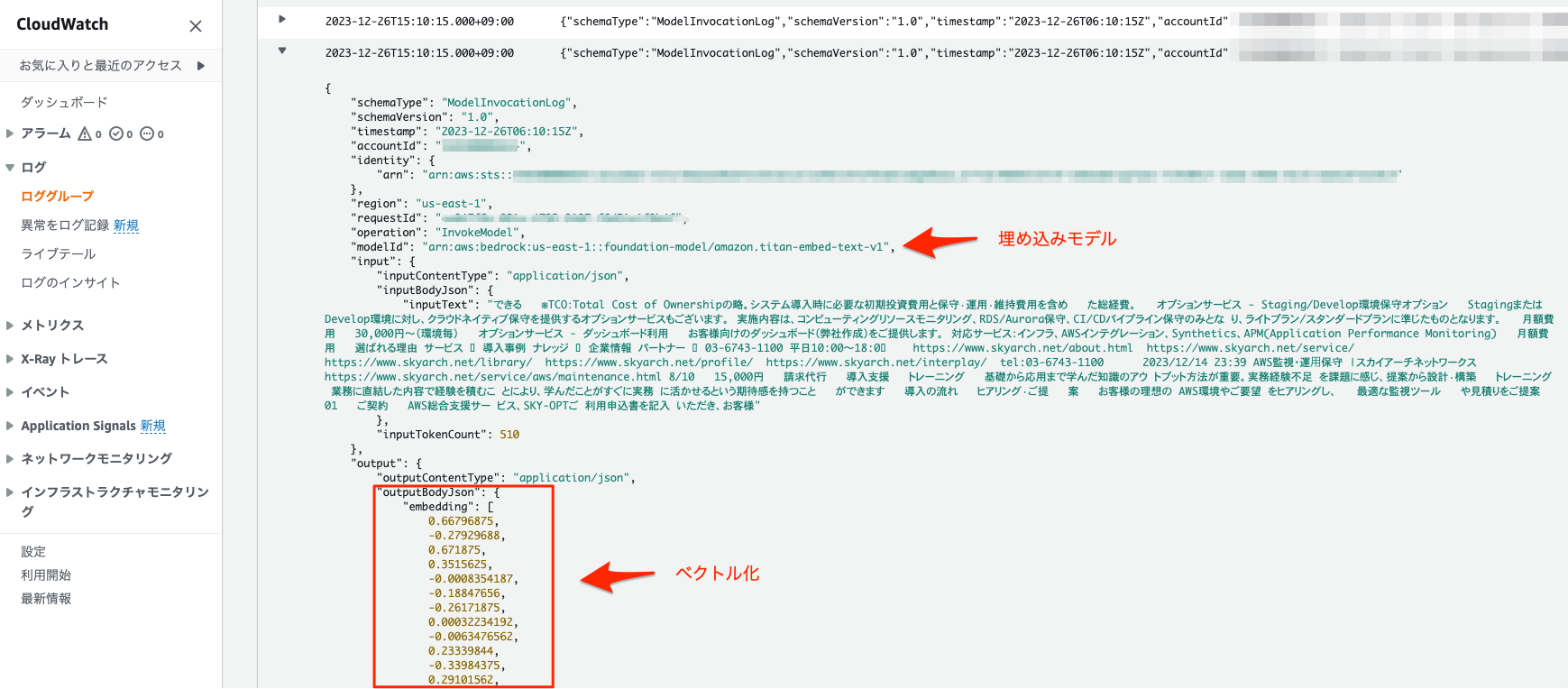
Amazon Titan Embeddingsによってベクトル化されてることがBedrockのログから確認出来ますね。
では次に作成されたRAGを使って動作確認に参りましょう!
動作確認
RAGに対応している基盤モデルとしては現在下記2モデルのみとなります。
・Claude Instant v1.2
・Claude v2
本ブログではClaude v2を用いて検証を進めます。
サンプルとして、弊社のセキュリティサービス「CyberNEO」のhtmlページの情報を元に質問してみようと思います。
コンソール画面のテストページにて検証
おお!きちんと正しい結果が返って来ていますね。
根拠となる文書のリンクも記載されています。
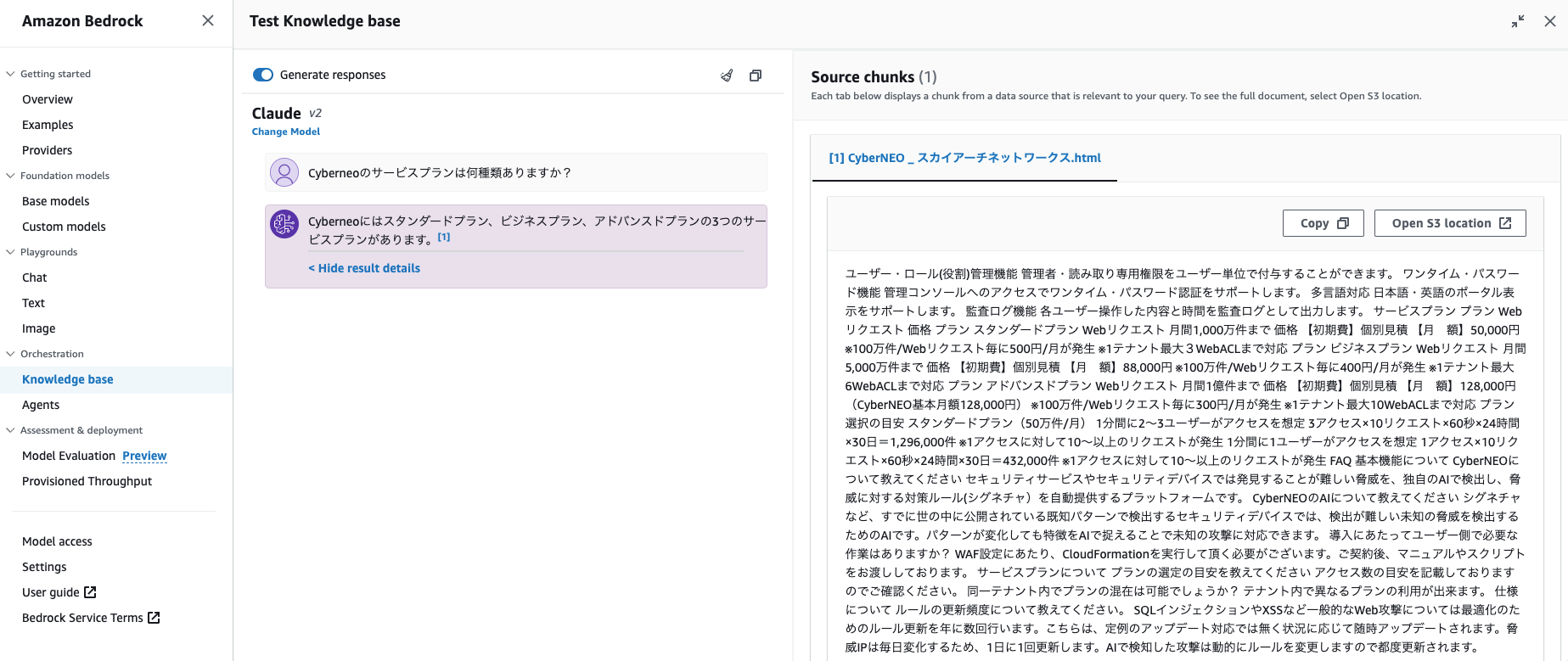
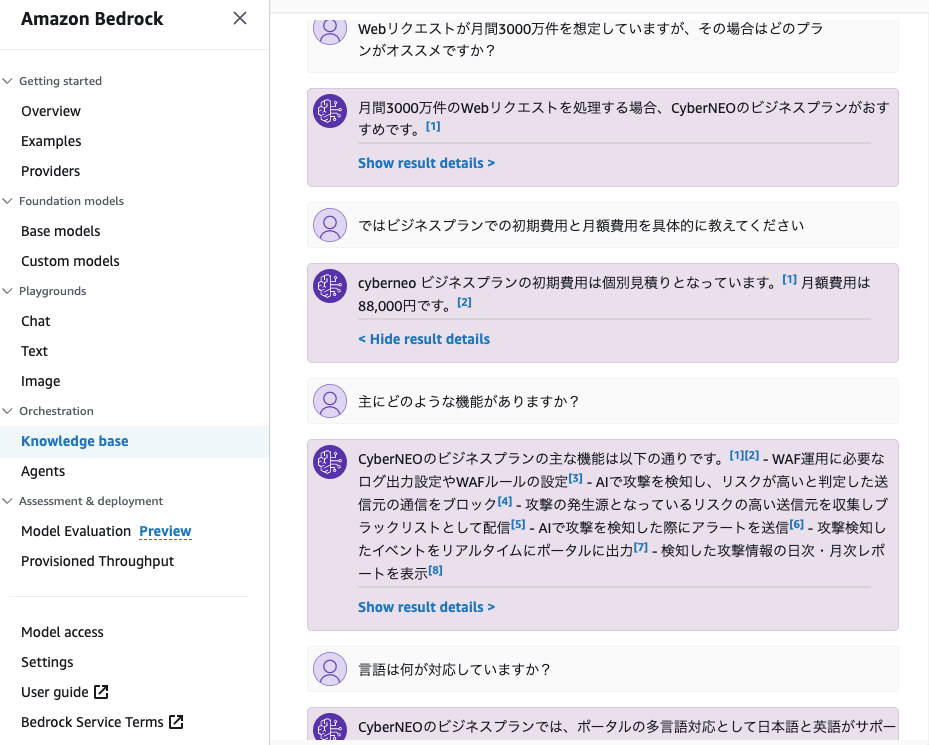
いい感じに結果が返って来てますね。
別の機会に、html以外のドキュメントで検証した際に同様の精度で返却されるか試してみたいと思います。
boto3を使っての検証
では次にコンソール画面でなく、SDK for Pythonであるboto3を用いて呼び出してみたいと思います。
リクエストのサンプルコード
boto3のドキュメントを参考に書きました。
下記設定に注意しながらコードを作成し、実行してみます!
・knowledgeBaseIdには構築したKnowledge base IDを設定
・boto3のclientは"bedrock-agent-runtime"を設定
・modelArnはanthropic.claude-v2を設定(詳細はこちら)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
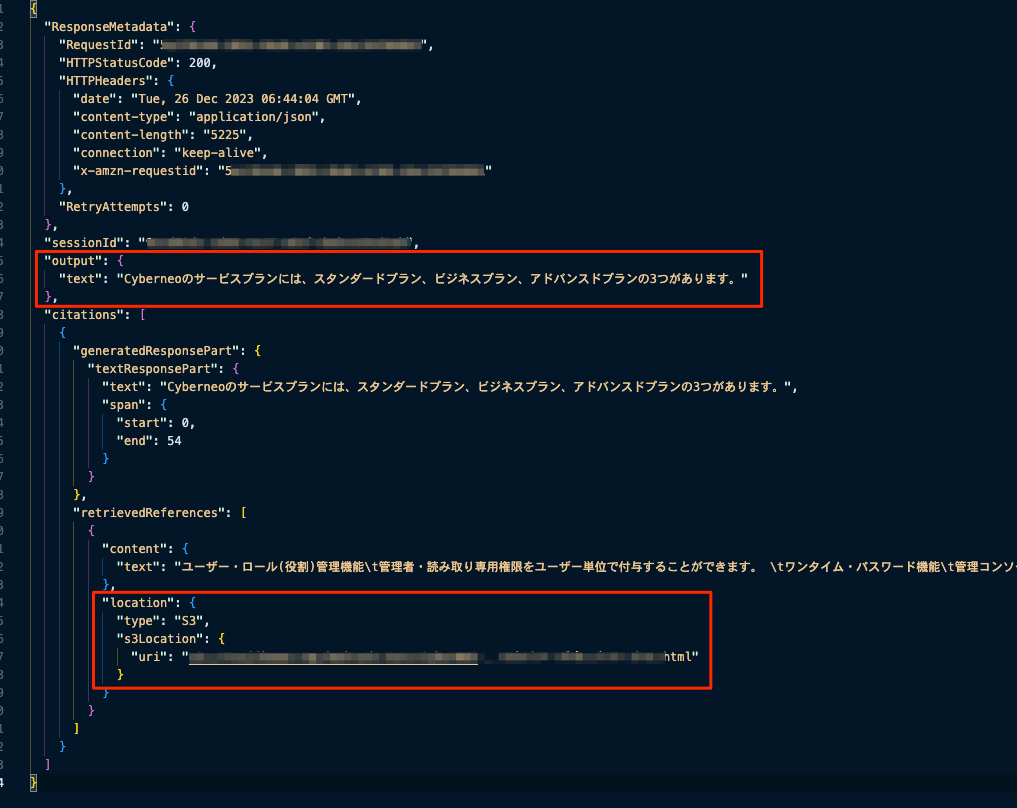
import boto3 import json def main(): client = boto3.client("bedrock-agent-runtime", region_name="us-east-1") response = client.retrieve_and_generate( input={ "text": "Cyberneoのサービスプランは何種類ありますか?", }, retrieveAndGenerateConfiguration={ "type": "KNOWLEDGE_BASE", "knowledgeBaseConfiguration": { "knowledgeBaseId": "xxxxxxxxx", "modelArn": "arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-v2", }, }, ) print(json.dumps(response, indent=2, ensure_ascii=False)) if __name__ == "__main__": main() |
レスポンス結果
コンソール画面からテストした結果と同様の結果が返却されていますね。
boto3を使うことで独自のアプリからも簡単に呼び出せることが確認出来ました。
注意点
料金
Knowledge base自体は料金かかりませんが、裏で実行される基盤モデルのAPI料金やOpenSearch Serverlessの料金が発生します。
削除時の挙動
Knowledge base自体は、一覧画面から削除が出来ますがOpenSearch Serverlessは自動的に削除されません。
OpenSearchのコンソール画面より個別に削除を行う必要があります。
無駄なコストが発生しないようにしましょう!
感想
さて、ここまでで簡単にRAGの構築が出来たことがお分かりになったかと思います。
今回の検証では期待値通りのレスポンスが返却されましたが、大量のデータや格納するデータの種類によっては期待値通りでない結果が返ってくることもあるかと思います。
そのため、実際に構築&検証する際には、食べさせるデータの整備やベクトルデータベース側の設定等のチューニング作業は発生するかと思います。
RAG構築自体は簡単になったため、チューニングの方に時間をかけれるのはいいことかなと思います。
またコスト面では、OpenSearch Serverlessは少しお高いサービスになりますので、最近ベクトルデータベースに対応したAmazon Aurora PostgreSQL(serverless v2)を使用することで費用を抑えることも可能になります。
こちらは別の機会に検証を進めてみようと思います。
投稿者プロフィール

-
2021/2にスカイアーチネットワークスにJoin。
(前職ではAIのシステム開発やPoCなどを主に担当)
2024 Japan AWS Top Engineers (Services)
2024 Japan AWS All Certifications Engineers
現在の業務では主にクラウドネイティブなWebアプリケーション/APIのインフラ構築から開発まで幅広く担当。
好きなAWSサービス:AWS CDK、Amazon Bedrock
趣味:読書と競馬鑑賞