This new capability offered by AWS improves the cluster scaling experience by increasing the speed and reliability of cluster scale-out, giving the user control over the amount of spare capacity maintained in the cluster, and automatically managing instance termination on cluster scale-in.
Previously, the workaround to have ECS Cluster Auto Scaling enabled is to create CloudWatch Alarms connected to the ECS Cluster CloudWatch Metrics (e.g., MemoryUtilization, CPUUtilization) and then integrate those alarms in the Auto Scaling Group of the ECS Cluster. With this, you will have to manage the number of EC2 instances you add or remove every time the alarms you set are triggered. You can read more on that here.
Capacity Provider
Going back to the new ECS Cluster Auto Scaling, to enable it, you will need to create the new ECS resource type called Capacity Provider. A Capacity Provider can be associated with an EC2 Auto Scaling Group (ASG). Through an ASG will an ECS Cluster have the optimum number of container instances, without creating additional CloudWatch Metric Alarms nor specifying the number of EC2 instances in case of scale out or in.
In particular, Capacity Provider uses Managed Scaling that utilizes an automatically-created scaling policy on the ASG, and a new scaling metric (Capacity Provider Reservation) to manage the optimum number of instances in the cluster; and in addition, Managed instance termination protection which enables container-aware termination of instances in the ASG when scale-in happens.
Creating Capacity Provider and ECS Cluster
To create a Capacity Provider, you will need an ASG first. An ASG can be created through the AWS console or AWS CLI. You may also opt to using the AWS SDK. An ASG, in turn, requires Launch Configuration so this needs to be created first.
In the AWS console, ASG and Launch Configuration sections can be found in the EC2 console. Using CLI:
Launch Configuration:
|
1 |
aws autoscaling create-launch-configuration --cli-input-json <launch-config-json> --user-data <user-data-txt-file> |
Auto Scaling Group:
|
1 |
aws autoscaling create-auto-scaling-group --auto-scaling-group-name <asg-name> --cli-input-json <asg-config-json> |
Capacity Provider:
|
1 |
aws ecs create-capacity-provider --cli-input-json <capacity-provider-config-json> |
Now you can finally create the ECS Cluster equipped with Capacity Provider:
|
1 |
aws ecs create-cluster --cluster-name <cluster-name> --capacity-providers <capacity-provider-name> --default-capacity-provider-strategy capacityProvider=<capacity-provider-name>,weight=1 |
Note: You need not to create a Launch Configuration and an ASG if you create the ECS Cluster using the EC2 Linux + Networking template. They are handled by AWS in the background. All you have to do is create a Capacity Provider and connect the pre-configured ASG to it. This is NOT possible if you create an EMPTY cluster.
Fargate and EC2 ECS Launch Types Comparison
In this section, Fargate (A) and EC2 ECS launch types with (B) and without (C) Capacity Provider are compared.
Setup
Three clusters are prepared, one each for the three launch types. All of them use the same task definition and container definition for the service.
(A) in the first place does not need any EC2 and container instance configuration as it is managed by AWS.
For (B), launch configuration and ASG created when the ECS Cluster was created are utilized. Capacity Provider was added with Managed Scaling option enabled.
Additional configurations are needed for (C) such as CloudWatch Metric Alarms mentioned earlier. One (1) EC2 instance is added every time the alarm is triggered.
Twenty (20) tasks are fired through updating the service definition (i.e., Number of tasks = 20).
Speed
(A) is the fastest in launching the 20 tasks as most of its resources are handled and optimized by AWS.
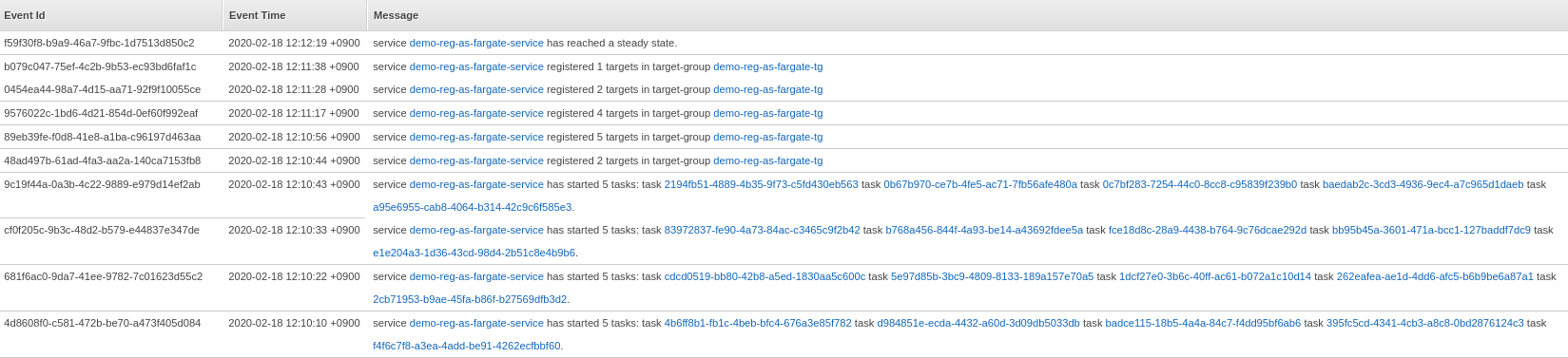
As shown in the image, it only took ~2 minutes for the 20 tasks to be launched and the service to reach a steady state.
(B) comes in second which took ~11 minutes to do the same job.
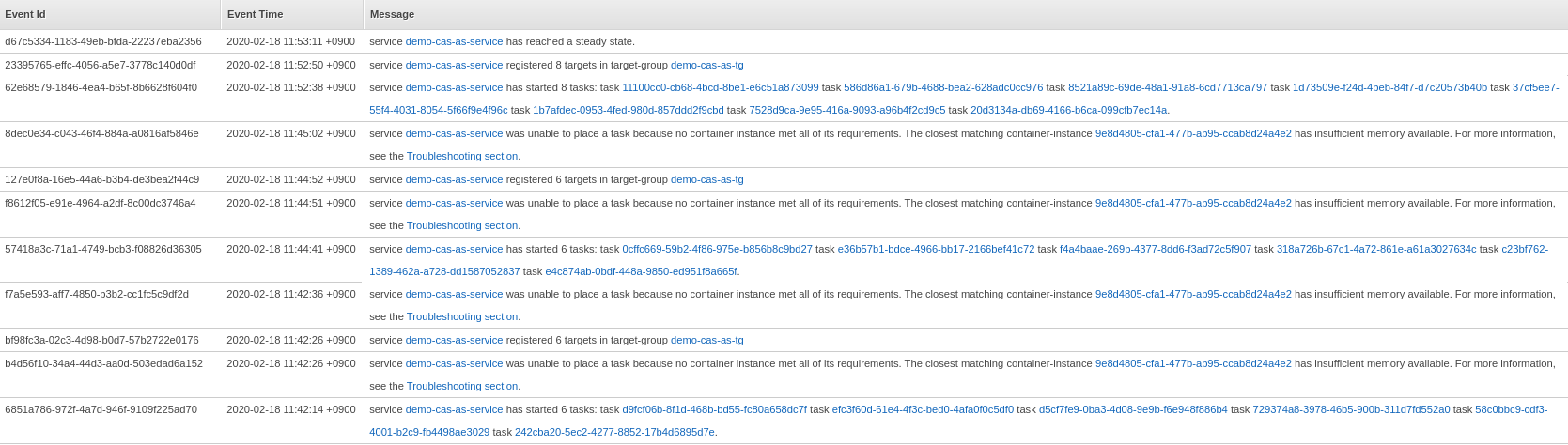
As seen, the service repeatedly failed to place the remaining tasks due to insufficiency in memory of the available container instances (EC2 instances). ASG through the Capacity Provider fired the necessary number of additional EC2 instances to accommodate the remaining tasks.
(C) is the slowest of the three mainly because it depends on the cluster's CPUUtilization and MemoryUtilization metric alarms. Also, since only 1 instance is added every alarm trigger, it took time for the optimum number of EC2 instances to be fired.
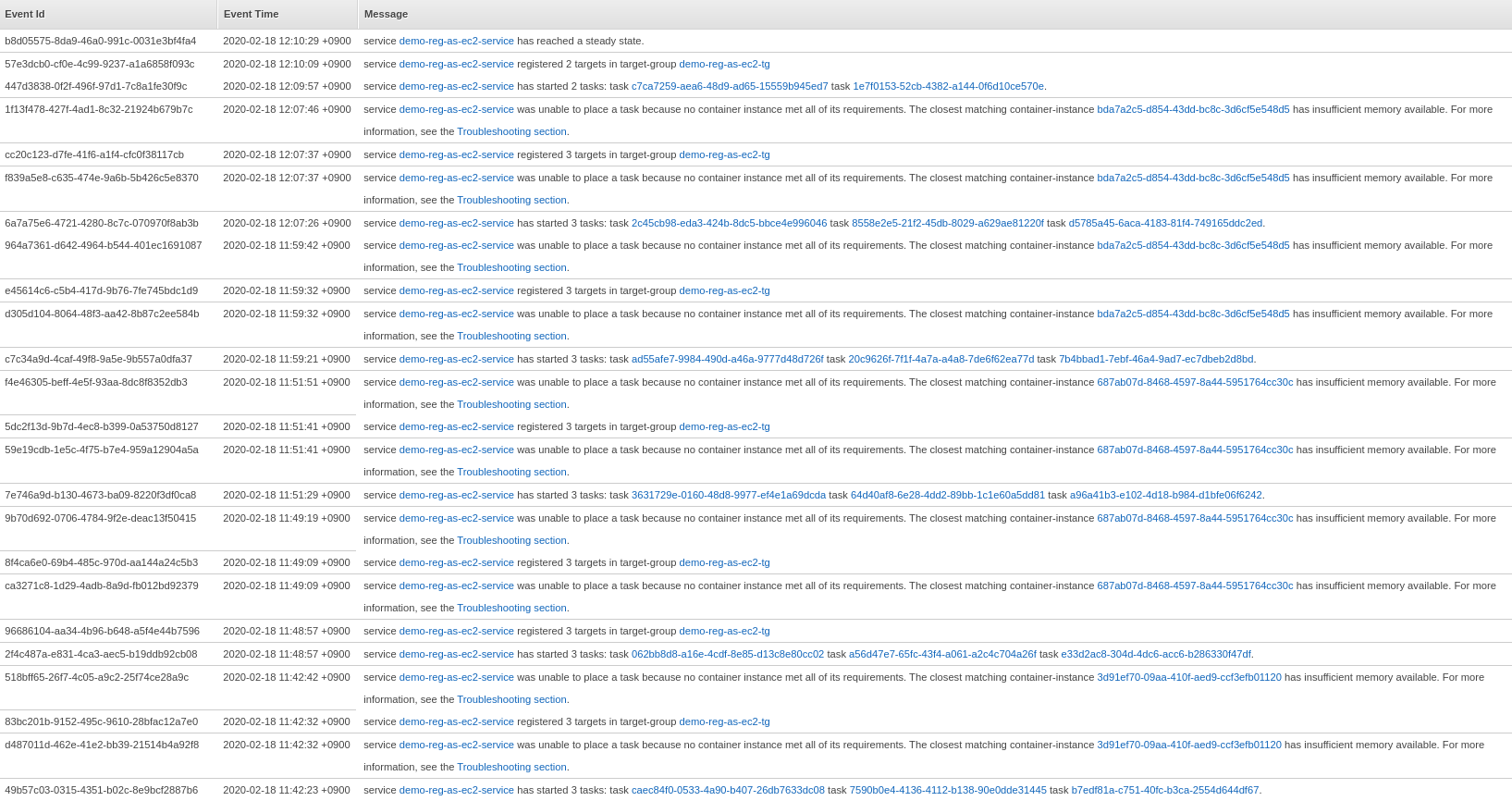
It took ~28 minutes for (C) to reach a steady state. This can be further improved by tweaking the CloudWatch Alarms thresholds and/or the number of instances fired each alarm trigger.
Zero Scale
(A) and (B) can both scale out from zero. For (C), however, it needs at least one container instance for the CloudWatch Metrics to record data; only then can it decide whether to add more instances or not.
References
- https://aws.amazon.com/blogs/compute/building-blocks-of-amazon-ecs/
- https://aws.amazon.com/about-aws/whats-new/2019/12/amazon-ecs-capacity-providers-now-available/
- https://aws.amazon.com/blogs/aws/aws-ecs-cluster-auto-scaling-is-now-generally-available/
- https://aws.amazon.com/blogs/containers/deep-dive-on-amazon-ecs-cluster-auto-scaling/
- https://github.com/aws/containers-roadmap/issues/76
Author Profile

-
Zabbixとお酒をこよなく愛す元バンドマン。
たぶん前世は風船。

![[AWS Fargate] Platform Version 1.4.0. Updates](https://www.skyarch.net/blog/wp-content/plugins/vk-post-author-display/assets/images/thumbnailDummy.jpg)





