前回はAmazonEFSを使ってみましたが
今回は同じくAWSのDataPipelineを使い、
EFSのバックアップをスケジューリングします。
そもそもEFSは高耐久性のファイルシステムですが、
それでも人間の手による誤削除の可能性はあるわけで、
やはりバックアップの必要性はあると思います。
DataPipelineに関してはWeb上にもろもろ説明がありますが、
今回は処理を定期実行するcronのような使い方をします。
設定した処理を、Pipelineによって起動したEC2が実行します。
概要
EFS領域のデータをS3へアップロードします。
具体的には、Pipelineによって作成されるEC2に下記の処理をさせます。
①EFSを /mnt にマウント
②EFS領域をS3バケットへアップロード
準備①EFS作成
バックアップ対象となるEFSを作成し、バックアップの成否判定の為に
EFS領域にファイル・ディレクトリを適宜作成します。
EFS作成・利用方法に関しては、こちらをご覧下さい。
準備②S3バケット作成
下記2つのバケットを作成します。
EFSバックアップ保管用バケット
…今回は「efs-backup-data-bucket」とします。
Pipeline実行ログ保管用バケット
…今回は「efs-backup-log-bucket」とします。
Pipeline作成
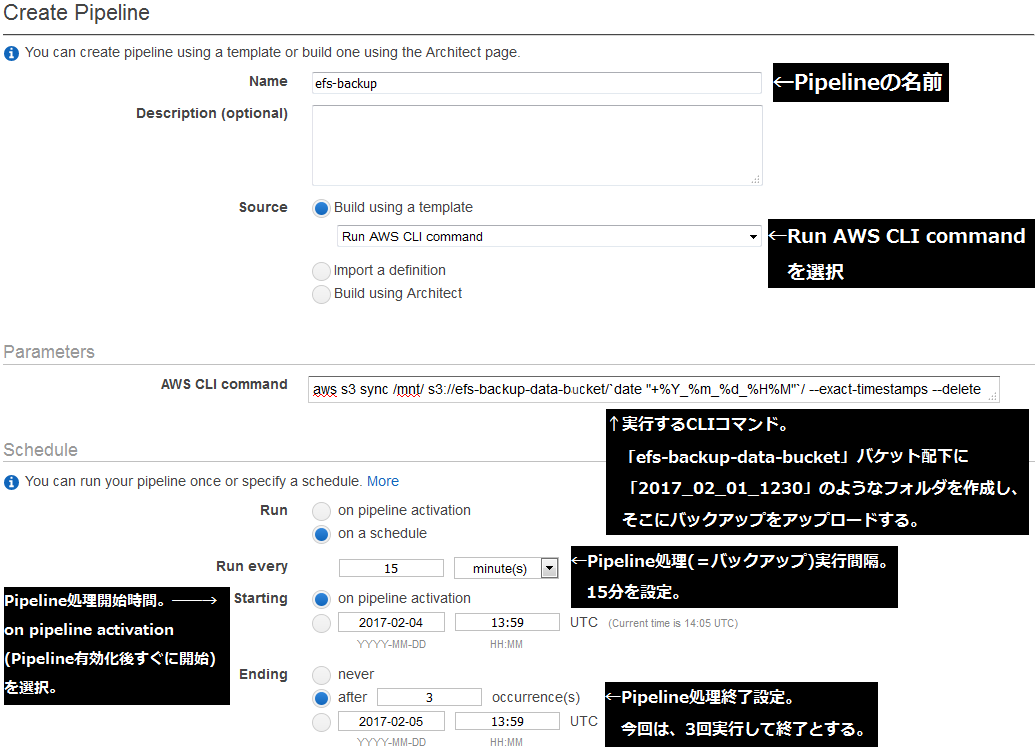
Data Pipelineの画面から、[Create Pipeline]を選択して設定画面に遷移します。
下記画像のように設定します。
|
1 2 |
※「Run AWS CLI Command」欄に入力したコマンド: aws s3 sync /mnt/ s3://efs-backup-data-bucket/`date "+%Y_%m_%d_%H%M"`/ --exact-timestamps --delete |
引き続き、ロギングとタグを設定します。
IAMロールの設定は今回の趣旨から外れるため省きますが、
デフォルトで適用されるロールには過多な権限が付与されている為
検証時以外は適切な(最小限の)権限に留めて下さい。
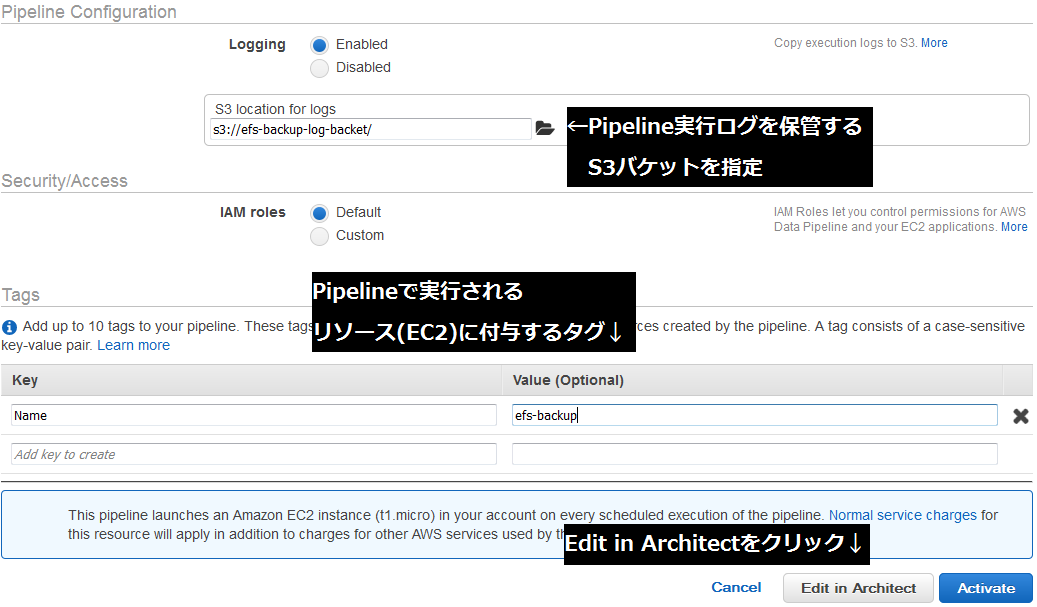 [Edit in Archtect]で2段階目の設定画面に遷移します。
[Edit in Archtect]で2段階目の設定画面に遷移します。「Activities」タブを開くと「Command」欄に実行するコマンドが記載されています。
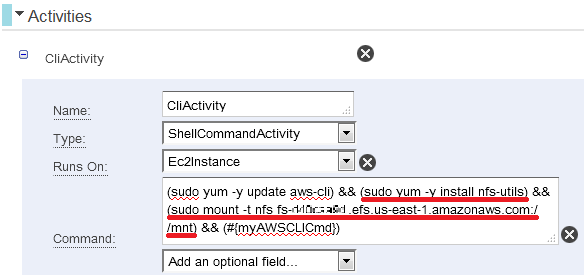
デフォルトではCLIのアップデート(sudo yum -y update aws-cli)と
CLIコマンドを実行する処理(※)しか記載されていない為、
nfs-utilsをインストールするコマンドとEFSをマウントするコマンド(赤下線)を追加しています。
※
#{myAWSCLICmd}というパラメータで定義されており、
「Parameters」タブを開くとそこに実際のコマンドが記載されている。
|
1 2 |
※「Command」欄に入力したコマンド: (sudo yum -y update aws-cli) && (sudo yum -y install nfs-utils) && (sudo mount -t nfs fs-********.efs.us-east-1.amazonaws.com:/ /mnt) && (#{myAWSCLICmd}) |
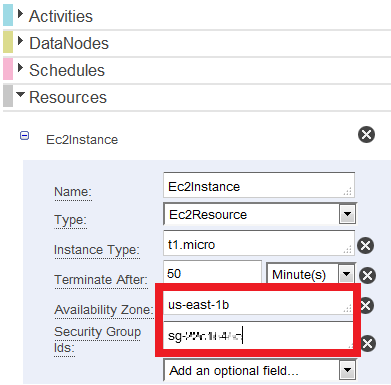
次に「Resource」タブを開き下記のように設定します。
Availability ZoneとSecurity Group Idsはデフォルトでは表示されていないので
[Add an optional field...]プルダウンからそれぞれ選択し、表示させて下さい。
それぞれ、EFSに接続できるものを入力しましょう。
最後に画面左上の[Activate]でPipelineを有効化します。

これで設定完了です。
指定したS3バケットに、15分ごとにバックアップフォルダおよび
その中身が格納されていれば成功です!
はまった部分など
・セキュリティグループでEC2→EFSが許可されていなかった
ごく初歩的な部分ですが…。
セキュリティグループを入力する欄がデフォルトで表示されるわけでないので
[Add an optional field...]プルダウンから「これかな?」というものを
探し出さなければなりません。
・デフォルトで使用するAMIの問題
AMI IDを指定しない場合のデフォルトAMIが2013年のAmazon Linuxとなっており
nfs-utilsが未インストールの為EFSをmountできない事象が発生していました。
上述の通り、sudo yum -y install nfs-utilsも実行コマンドに加えて解決しました。
投稿者プロフィール
- 2015年8月入社。弊社はインフラ屋ですが、アプリも作ってみたいです。